1. Gradient descent
: 오차를 미분하여 weight를 update하는 방법.
- 문제에 적합한 Loss function을 정의하고, 그것이 최소가 되는 방향을 찾아 나아간다.
- Error function을 각 변수들로 편미분하여 기울기를 구한다.
-> 해당 기울기의 방향으로 움직여 local minimum을 향한다.
- Delta Rule
: Perception Rule과 거의 유사하다.
-> 전체 학습 데이터에 대한 오차를 최소화 하는 방법이다.
-> Threshold가 아닌 Gradient Decent 방법을 사용한다.
=> Threshold가 기 때문에 출력은 다음과 같이 정의된다.
\( o(\overrightarrow{x}) = \overrightarrow{x} \cdot \overrightarrow{x} \)
-> 입력에 가중치를 곱한 바로 출력이 된다.
- Mean Square : 평균 자승
-> Delta Rule에서는 에러를 정의할 때 평균 자승을 반드시 2로 나누어 준다.
=> Square를 미분 시 발생하는 2를 없애기 위해서
\( Error = \frac{1}{2} \sum(t_d - o_d)^2 \)
-> Delta Rule에서 error로 사용하는 식
-> \( t_d, o_d\)는 각각 목표 값, 출력 값 (현재 학습에 대한 결과)
- Perception Rule에서는 오직 두 뉴런간의 weight만 정의한다.
- Delta Rule에서는 목표 패턴을 사용하고, 목표 패턴과 출력 값의 차이인 Error를 최소하 하는 것을 목표로 한다.
- 최소화 하는 방법은 간단하다.
-> Error를 편미분해준다.
=> 이 때 error를 편미분 할 수 있도록, activation 함수가
-> 각각의 편미분 값에 대해 독립적으로 지정된 weight를 곱해준다.
-> 해당 값을 위에서 얻은 결과만큼 update 해준다.
==> 나중에 다시 정리 // 이게 중요한게 아님...
** 요약하면 정답과 현재 결과 사이의 오차에 입력의 크기에 비례하여 가중치를 오차가 줄어드는 방향으로 업데이트 하는 것이다.
2. Back-propagation
: Hidden node에서 오차를 미분하여 weight를 update하는 방법
- Delta Rule을 Multi Layer Perceptron, 즉, 여러 계층을 가진 Neural Network에 적용하기 위해 고안된 알고리즘이다.
- 앞 쪽 layer에서 부터 각층의 output을 계산해 나간다.
-> 맨 마지막 layer에 도달하면 target pattern (참 값)과 비교하여 error를 구한다.
-> 다시 제일 마지막 layer에서 부터 역으로 내려오면서 각 노드 마다의 partial error를 계산한다.
-> Partial error를 input만큼 곱해서 역순으로 error를 학습한다.
=> 각 노드에 대한 partial error를 feed backward한다.
예시)
: 2-layer neural network
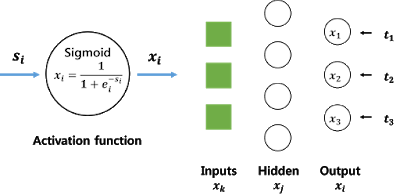
-> input layer는 보통 세지 않으므로 2 layer가 된다.
-> 모든 activation function은 sigmoid 함수로 통일한다.
- Error function, \( E \)는 다음과 같다.
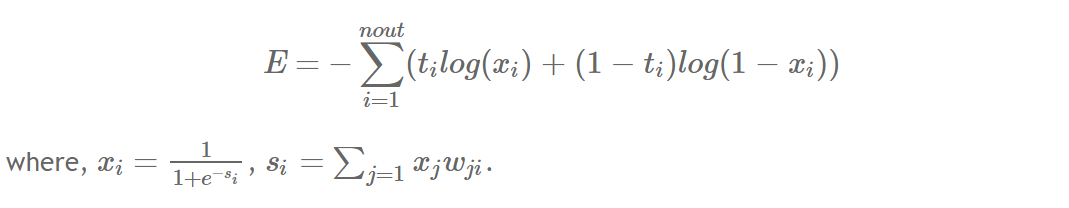
- \( s_0 \)가 입력되었을 때, \( s_0 \)는 activation 함수 (sigmoid function)과 곱해진다.
-> 이에 대한 결과로 나온 출력값 \( x_0 \)는 다시 가중치 \( w_0 \)와 곱해진다.
=> \( x_0 w_0 \)은 \(s_1\)가 되어 다음 activation 함수로 입력되고, 이와 같은 과정을 반복한다.
- 수식을 이해하기 위해서 값을 대입한다.
=> 참값이 \( t_i = 1\) 일 때, 신경망이 계산한 답이 1일 확률이 0 이라는 출력 (\( x_i =0 \))이 나왔다면, \( E = \infty \)가 나온다.
=> 반대로 \( t_i = 1\) 일 때, \( x_i = 1 \) 이라면, \( E = 0 \)으로 최솟값을 갖는다.
- 오차 값을 줄이는 방향으로 update 하기 위해서 gradient descent 개념을 사용한다.
- 이때 data의 input을 바꾸는 것이 목적이 아닌, input에 대한 output에 영향을 주는 weight, \( w \)들이다.
-> 따라서 각 layer의 weight에 한 \( E \) 함수의 gradient를 계산하고, 이 변화량을 원레 weigh에 반대 방향으로 더해준다. (gradient descent)
- 학습의 순서는 위에 서술한 것과 동일하다.
-> input layer로 부터 각 layer를 지나치며 weight들을 곱한다.
-> 이후, activation function을 지난다.
-> 마지막 output layer에서 참값과 비교하여 오차값을 계산한 이후 (feed forward 과정 종료)
-> 순차적으로 update하며 back propagation다.
- 따라서 가장 첫번째 weight인 output과 hidden 사이의 weight를 바꿔보자.
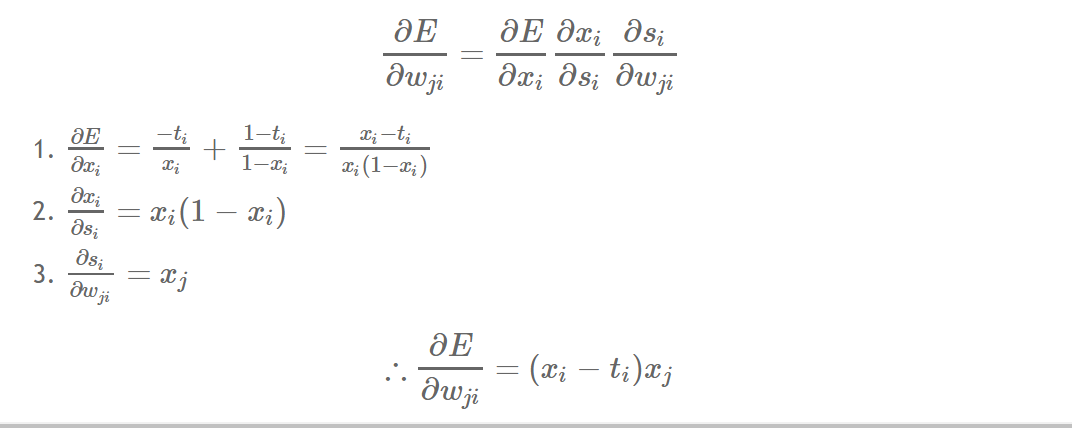
-> 가장 윗 식의 우변의 세 개의 항중 앞의 두 항을 우선 곱한 것을 주목하자.
=> 결과가 gradient descent 와 동일한 모습으로 나온다.
- 같은 논리로 그 다음 hidden과 input 간의 weight에 대한 변화량을 계산하면 다음과 같다.
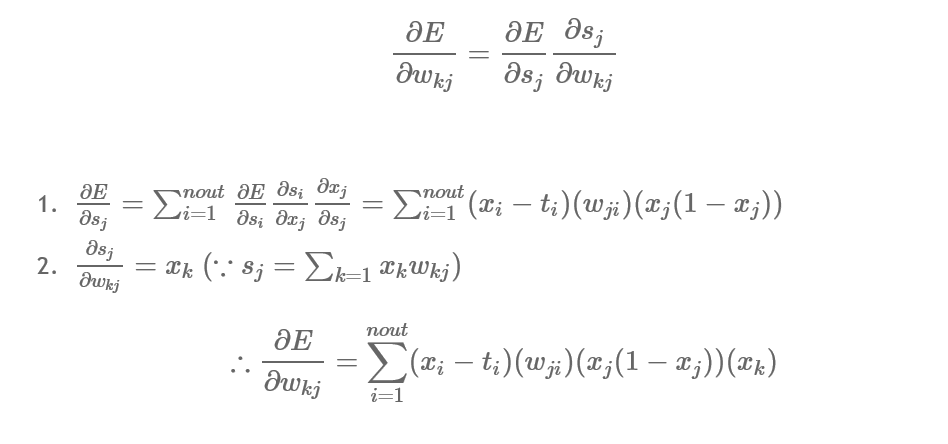
-> 여기서 \( x_k \)는 feed forward 할 때도 \( i = {1, \cdots, nout} \)까지 모든 값에 영향을 주기 때문에 back propagation 시에도 모든 값들을 고려하여 계산해야 한다.
-> 여기도 제일 윗식 우변 첫번째 항 (\( \partial E \over{\partial s_j} \))을 구한 것을 확인할 수 있다.
=> 해당 논리를 기억하면 위에서 유도한 식들을 general muliplayer network로 장하는 것이 매우 쉬워진다.
** 각 layer의 \( \partial E \over{\partial w_{ij}} \)를 구하고 싶을 때, \( \partial E \over{\partial s_{ㅓ}} \)를 계산하고, \( \partial s_j \over{\partial w_{kj}} = x_k\)_{kj}} = x_k\)를 곱해주면 된다.
3. Others
1) Hebbian learning
: 기본 신경망 학습규칙, 무감독 학습 방법에 사용되었다.
- 어떤 세포가 다른 세포의 활성에 지속적으로 도움을 준다면, 이 둘의 관계에 연결 가중치를 증가시켜야 한다.
-> 다시 말해, 두 뉴런이 모두 1이 되면 (activated). 둘 사이의 weight를 증가시킨다.
=> Local 하게 오직 2개의 뉴런 관계만을 가지고 학습하는 방법이다.
\( W^{new}_{ij} = W^{old}_{ij} +\alpha a_ib_i \)
\{ \alpha \} : learing rate (학습률)
- \( a, b \) 사이에는 곱 법칙이 작용한다. (둘 다 1이어야 결과값이 1)
* Hebbian learning은 원래 무감독 학습 모델이나, 지금은 발전하여 목적패턴이 추가되면서 감독학습으로 발전하였다.
-> 감독학습은 인위적으로 학습을 제어할 수 있다.
=> Delta rule을 의미한다.
2) Perception rule
: 두 개의 뉴런간의 weight를 학습할 때 목적 패턴과 오차를 이용하는 학습 방법이다.
- 오차가 발샐했을 때 입력이 1인 뉴런에 대해서만 오차만큼 학습시킨다.
- 어떤 세포가 활성되었을 때, 다른 세포가 잘못된 출력을 낸다.
-> 이때, 잘못된 세포의 출력값과 참값의 차이에 비례하여 weight를 조절한다.
\( W^{new}_{ij} = W^{old}_ij + \alpha a_i(t_j - b_j) \)
\( t_j\) : 목적 패턴 (위의 참값), \( t_j - b_j \) : 오차
- 오차가 0 일 때, 완벽하게 정답을 낸 것이다.
-> 즉, 학습하지 않는다.
- 오차 값의 크기가 0 보다 크면, 오차가 존재하는 것이다.
-> 오차에 대해 \( a_i \)가 활성화 된 만큼 학습한다.
- Perception rule은 기존의 Hebbian Learning에서 목적 패턴 (\( t_j \))이라는 개념을 도입하여 Supervised Learning을 한 것으로 생각할 수 있다.
-> 각 weight를 랜덤하게 설정한 후, 위의 방식으로 training하여 목적패턴에 가까워지게 할 수 있다.
예제)
: Perception rule을 이용하여 AND gate를 학습한다.
- X가 input, O가 목적 패턴, learning rate는 0.5, 초기 weight는 모두 1로 가정.
- Activation function은 step function이다.
- 각 weight는 input에 적용되는 것으로 가정한다.
- \( X = {x_1, x_2, x_3} \)
X1 : {1, 0, 0} // O1 : 0
X2 : {1, 0, 1} // O2 : 0
X3 : {1, 1, 0} // O3 : 0
X4 : {1, 1, 1} // O4 : 1
STEP 0
: \(w_1\) = 1, \(w_2\) = 1, \(w_3\) = 1
- weight summation = \( w_1x_1 + w_2x_2 + w_3x_3 > 0 \) 이므로, output은 1이 된다.
- 목적 패턴 O1 = 0 이므로 오차 = O1 - output = -1
- STEP 0에서 켜져있는 X는 \( x_1 \)이므로, 이에 해당하는 \( w_1 \)을 학습시킨다.
- \( w_1(new) = w_1(old) + (learning rate) (O1-output) = 1 + 0.5* -1 = 0.5 \)로 update한다.
STEP 1
: \(w_1\) = 0.5, \(w_2\) = 1, \(w_3\) = 1
STEP 2
: \(w_1\) = 1, \(w_2\) = 1, \(w_3\) = 0.5
STEP 3
: \(w_1\) = -0.5, \(w_2\) = 0.5, \(w_3\) = 0.5
STEP 4
: \(w_1\) = -0.5, \(w_2\) = 0.5, \(w_3\) = 0.5
- STEP 4 까지의 data set을 완료한 결과는 다음과 같다.
-> \(w_1\) = -0.5, \(w_2\) = 0.5, \(w_3\) = 0.5
=> 위의 X1, X2, X3, X4 모두를 계산해도 모두 만족한다.
- Training data set의 다양성과 갯수가 많고, learning rate를 작게 잡을수록 정교한 학습이 가능하다.
- Perception rule은 XOR 같은 선형 분리가 불가능한 문제에서는 학습 할 수가 없다.
'Study > Reinforcement learning' 카테고리의 다른 글
| 강화학습_(8) - Dynamic Programming (DP) (0) | 2019.11.07 |
|---|---|
| 강화학습_(7) - Markov Decision Process (MDP) (0) | 2019.11.07 |
| 강화학습_(5) - 머신 러닝 분류 - 지도 학습, 비지도 학습, 강화 학습 (0) | 2019.10.30 |
| 강화학습_(4) - Math Preliminary_2 (0) | 2019.10.23 |
| 강화학습_(4) - Math Preliminary_1 (0) | 2019.10.22 |