이번 프로젝트에서는 3장에서 보았던 CIFAR-10 데이터셋의 분류 모델을 다시 사용한다.
1단계: 의존 라이브러리 임포트하기
#import dependencies
import keras
from keras.models import Sequential
from keras.utils import np_utils
from keras.preprocessing.image import ImageDataGenerator
from keras.layers import Dense, Activation, Flatten, Dropout, BatchNormalization
from keras.layers import Conv2D, MaxPooling2D
from keras.datasets import cifar10
from keras import regularizers, optimizers
import numpy as np # 수학적 연산을 제공
from matplotlib import pyplot
2단계: 데이터 내려받기 및 준비
이번 프로젝트에서 사용하는 CIFAR-10 데이터셋은 32x32 크기의 컬러 이미지 60,000장으로 구성되며 10개의 카테고리가 부여된 50,000장 훈련 데이터와 10,000장 테스트 데이터로 분할되어 있다.
케라스에서 제공되는 해당 데이터셋은 이미 전처리가 완료되고 위와 같이 분할되어 있어, 다시 훈련 데이터에서 5,000장의 검증 데이터를 분할한다.
# download and split the data
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
(x_train, x_valid) = x_train[5000:], x_train[:5000]
(y_train, y_valid) = y_train[5000:], y_train[:5000]
print("training data = ", x_train.shape)
print("valid data = ", x_valid.shape)
print("testing data = ", x_test.shape)

출력된 튜플의 요소는 (데이터 수, 이미지 폭, 이미지 높이, 채널)을 의미한다.
1) 데이터 정규화
각 픽셀값에서 픽셀값의 평균을 빼고 표준편차로 나누는 방법으로 이미지의 픽셀값을 정규화한다.
# Normalize the data to speed up training
mean = np.mean(x_train, axis=(0,1,2,3))
std = np.std(x_train, axis=(0,1,2,3))
x_train = (x_train-mean)/(std+1e-7)
x_valid = (x_valid-mean)/(std+1e-7)
x_test = (x_test-mean)/(std+1e-7)
2) 레이블에 원-핫 인코딩 적용
훈련, 검증, 테스트 데이터의 레이블에 원-핫 인코딩을 적용한다.
# one-hot encode the labels in train and test datasets
# we use “to_categorical” function in keras
num_classes = 10
y_train = np_utils.to_categorical(y_train,num_classes)
y_valid = np_utils.to_categorical(y_valid,num_classes)
y_test = np_utils.to_categorical(y_test,num_classes)
3) 데이터 강화하기
실제 문제에서는 신경망이 예측을 틀리거나 잘 탐지하지 못하는 이미지를 직접 보고 왜 그렇게 되었는지 생각해 봐야 한다.
회전을 잘 탐지 못 하면, 이미지를 회전한 데이터를 추가하는 식으로!
이와 같이 가설-실험-평가 과정을 반복한다.
datagen = ImageDataGenerator(
rotation_range = 15,
width_shift_range = 0.1,
height_shift_range = 0.1,
horizontal_flip = True,
vertical_flip = False
)
datagen.fit(x_train) # 훈련 데이터를 대상으로 변형된 데이터 생성
3단계: 모델 구조 정의하기
3장에선 3CONV + 2FC를 간략화한 신경망을 구성했다.
이번 프로젝트에서는 층수를 더욱 늘려본다. 6CONV + 1FC
- 모든 합성곱층 뒤에 풀리층을 배치하는 대신 하나씩 걸러 배치한다. 이는 VGGNet을 참고한 것이다.
- kernel_size 3x3, 풀링층 pool_size 2x2
- 모든 합성곱층 뒤에 드롭아웃층을 배치한다. p는 0.2~0.4 사이의 값
- 모든 합성곱층 뒤에 배치 정규화층을 추가해서 합성곱층의 출력을 정규화한다.
- 케라스를 사용하면 L2 정규화를 합성곱층의 설정으로 적용할 수 있다.
# build the model
# number of hidden units variable
# we are declaring this variable here and use it in our CONV layers to make it easier to update from one place
base_hidden_units = 32
# l2 regularization hyperparameter
weight_decay = 1e-4
# instantiate an empty sequential model
model = Sequential()
# CONV1
# notice that we defined the input_shape here because this is the first CONV layer.
# we don’t need to do that for the remaining layers
model.add(Conv2D(base_hidden_units, (3,3), padding='same',
kernel_regularizer=regularizers.l2(weight_decay),
input_shape=x_train.shape[1:]))
model.add(Activation('relu'))
model.add(BatchNormalization())
# CONV2
model.add(Conv2D(base_hidden_units, (3,3), padding='same',
kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Activation('relu'))
model.add(BatchNormalization())
# POOL + Dropout
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.2))
# CONV3
model.add(Conv2D(2*base_hidden_units, (3,3), padding='same',
kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Activation('relu'))
model.add(BatchNormalization())
# CONV4
model.add(Conv2D(2*base_hidden_units, (3,3), padding='same',
kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Activation('relu'))
model.add(BatchNormalization())
# POOL + Dropout
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.3))
# CONV5
model.add(Conv2D(4*base_hidden_units, (3,3), padding='same',
kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Activation('relu'))
model.add(BatchNormalization())
# CONV6
model.add(Conv2D(4*base_hidden_units, (3,3), padding='same',
kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Activation('relu'))
model.add(BatchNormalization())
# POOL + Dropout
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.4))
# FC7
model.add(Flatten())
model.add(Dense(num_classes, activation='softmax'))
# print model summary
model.summary()
4단계: 모델 학습하기
학습 구현 코드를 보기 전에 몇몇 하이퍼파라미터를 결정하는 전략을 설명한다.
- batch_size :
미니배치와 관련된 하이퍼파라미터다. 값이 클수록 학습 속도가 빨라진다. 초기값을 64로 설정하고 두 배씩 올려 속도를 조절한다. 이때 메모리를 고려해야 한다. - epochs :
초깃값을 50으로 설정했으나, 오차가 계속 감소한다면 최대 에포크를 늘려야 한다. - 최적화 알고리즘 :
Adam을 사용했다.
학습 코드는 다음과 같다.
# training
batch_size = 128
epochs = 125
from keras.callbacks import ModelCheckpoint
checkpointer = ModelCheckpoint(filepath='model.10epochs.hdf5', verbose=1,
save_best_only=True) # 가장 성능이 좋았떤 가중치를 저장할 파일의 경로를 지정하고, 개선된 경우만 저장하도록 설정
# you can try any of these optimizers by uncommenting the line
# optimizer = keras.optimizers.rmsprop(lr=0.001,decay=1e-6)
# optimizer = keras.optimizers.adam(lr=0.0005,decay=1e-6)
optimizer = keras.optimizers.rmsprop(lr=0.0001,decay=1e-6) # Adam 최적화 알고리즘
# 교차 엔트로피 손실 함수
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
history = model.fit_generator(datagen.flow(x_train, y_train, batch_size=batch_size),
callbacks=[checkpointer], steps_per_epoch=x_train.shape[0] // batch_size, epochs=epochs,
verbose=2, validation_data=(x_valid, y_valid))
# GPU를 사용해서 학습을 진행하면서 동시에 CPU를 사용해서 실시간으로 데이터 강화를 수행하도록 한다.
# callback으로 설정된 checkpointer는 가중치를 저장하는 역할을 한다. 이 외에도 조기 종료 함수를 콜백으로 추가할 수 있다.
5단계: 모델 평가하기
케라스에서 제공하는 evaluate 함수를 사용해서 모델을 평가한다.
# evaluating the model
scores = model.evaluate(x_test, y_test, batch_size=128, verbose=1)
print('\nTest result: %.3f loss: %.3f' % (scores[1]*100,scores[0]))
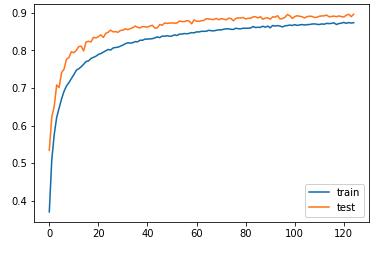
6단계: 학습 곡선 그리기
모델의 학습 과정과 과적합 및 과소적합 발생 여부를 판단하기 위해 학습 곡선을 그린다.
# plot learning curves of model accuracy
pyplot.plot(history.history['acc'], label='train')
pyplot.plot(history.history['val_acc'], label='test')
pyplot.legend()
pyplot.show()
8단계: 추가적인 개선
90% 정도면 상당한 성능이다. 하지만 아직 개선의 여지가 남아있다.
- 최대 에포크 수 늘리기 :
123 에포크까지 성능이 계속 개선되고 있으므로, 150 내지 200까지 늘려서 성능을 관찰한다. - 층수 늘리기
- 학습률 하향 :
학습률을 낮춘다. 최대 에포크 수를 함께 늘려야 한다. - 다른 CNN 구조 적용 :
인셉션이나 ResNet과 같은 구조를 적용한다. - 전이학습 적용 :
기존에 학습을 마친 신경망을 이용해서 적은 학습 시간으로 더 높은 성능을 달성한다. 6장에서 다룬다.
'Study > Vision & Deep Learning' 카테고리의 다른 글
| [VISION] 비전 시스템을 위한 딥러닝(7) - R-CNN, SSD, YOLO를 이용한 사물 탐지 (1) | 2023.05.31 |
|---|---|
| [VISION] 비전 시스템을 위한 딥러닝(6) - 전이학습 (0) | 2023.05.30 |
| [VISION] 비전 시스템을 위한 딥러닝(3) - 딥러닝 프로젝트 시동걸기 (0) | 2023.05.29 |
| [VISION] 비전 시스템을 위한 딥러닝(2) - 프로젝트: 컬러 이미지 분류 실습(CNN) (0) | 2023.05.29 |
| [VISION] 비전 시스템을 위한 딥러닝(1) - 합성곱 신경망 (2) | 2023.05.28 |