CIFAR-10 데이터셋은 컴퓨터 비전 분야에서 널리 알려진 사물 인식 문제 데이터셋입니다.
8천만 장으로 구성된 데이터셋에서 추린 32x32 크기의 컬러 이미지 6만 장으로 구성되었으며, 클래스당 6천 장씩 10가지 클래스로 구분된다.
1단계: 데이터셋 읽어 들이기
가장 먼저 할 일은 데이터셋을 읽어 들여 학습 데이터와 테스트 데이터로 분할하는 것입니다.
import keras
from keras.datasets import cifar10
# load the pre-shuffled train and test data
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
# 미리 무작위로 섞은 데이터를 학습 데이터와 테스트 데이터로 분할한다.# Visualizing first 24 images
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
fig = plt.figure(figsize=(20,5))
for i in range(36):
ax = fig.add_subplot(3, 12, i + 1, xticks=[], yticks=[])
ax.imshow(np.squeeze(x_train[i]))
2단계: 이미지 전처리
일반적으로 모데르이 학습을 시작하기 전에 약간의 데이터 클린징과 전처리를 거칩니다.
손실 함수의 그래프는 동그란 사발 모양이지만 특징 배율에 따라 타원형 사발 모양이 됩니다.
경사 하강법을 사용할 때는 모든 특징의 배율을 비슷하게 맞추는 편이 좋습니다. 그렇지 않으면 학습 시간이 길어집니다.
1) 이미지 픽셀값 정규화 하기
다음 코드를 이용해 정규화 할 수 있습니다.
# 픽셀값 정규화
# rescale [0,255] --> [0,1]
x_train = x_train.astype('float32')/255
x_test = x_test.astype('float32')/255
2) 레이블 준비하기 (원-핫 인코딩)
입력 데이터는 픽셀값의 강도를 나타내는 값이 모여 구성되는 행렬의 형태입니다.
레이블은 어떻게 나타낼까요?
데이터셋에 포함되어 있는 이미지는 유형에 따라 레이블이 부여되어 있습니다.
해당 데이터셋은 텍스트 레이블이 부여되어 있으며, 이 텍스트 레이블 역시 컴퓨터가 다룰 수 있는 숫자 형태로 변환해야 합니다.
이때, 주로 원-핫 인코딩을 사용합니다. 이는 범주형 변수를 숫자로 변환하는 방법 중 하나입니다.
from keras.utils import np_utils
# one-hot encode the labels
num_classes = len(np.unique(y_train))
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
3) 훈련 데이터와 테스트 데이터 분할하기
학습 데이터를 훈련과 테스트 데이터로 분할합니다. 훈련 데이터는 다시 훈련 데이터와 검증 데이터로 분할하는 것이 표준적인 방식입니다.
- 훈련 데이터: 모델을 학습하는데 사용
- 검증 데이터: 하이퍼파라미터를 튜닝할 때 훈련 데이터에 치우치지 않도록 하는 데이터. 검증 데이터에서 학습한 내용이 모델 설정에 끼어들면 모델 평가가 편향된다.
- 테스트 데이터: 모델의 성능을 최종 판단하기 위해 사용하는 데이터
# break training set into training and validation sets
(x_train, x_valid) = x_train[5000:], x_train[:5000]
(y_train, y_valid) = y_train[5000:], y_train[:5000]
# print shape of training set
print('x_train shape:', x_train.shape)
# print number of training, validation, and test images
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
print(x_valid.shape[0], 'validation samples')
3단계: 모델 구조 정의하기
대부분의 딥러닝 프로젝트는 간단한 층을 쌓아 올려 데이터 증류를 구현하는 형태입니다.
앞서 알아보았던 CNN 주요 구성 요소는 합성곱층, 풀링층, 전결합층, 활성화 함수입니다.
신경망 구조를 설계하는 방법
합성곱층과 풀링층은 몇 개나 배치해야 할까요?
AlexNet, ResNet, Inceptin의 문헌 등을 참고해서 핵심 아이디어를 정리해 보라고 권고하고 있습니다.
이들의 구현을 모방해서 자신의 프로젝트에 적용하다 보면 당면한 문제에 어떠한 구조가 가장 접합한지 알아보는 직관을 가질 수 있습니다.
대표적인 합성곱 신경망의 구조는 다른 게시물에서 설명하겠습니다.
그전까지 알아둬야 할 사항은 다음과 같습니다.
- 층수가 많을수록 복잡한 문제 학습 가능. 대신 계산 복잡도가 증가하고 과적합 문제 발생 가능성 높음
- 입력 임미지가 신경망 층을 거칠 때 크기는 줄고 깊이는 증가
- 일반적으로 필터 크기가 3x3인 합성곱층 두세 층 뒤로 역시 필터 크기가 2x2인 풀링층을 하나 배치하는 정도로 설계 시작.
이 정도면 작은 데이터셋을 다룰 수 있다. - 그리고 이미지 크기가 적절해질 때까지 (4x4, 5x5 정도) 합성곱과 풀링층을 추가한다. 마지막으로 분류를 담당할 전결합층을 끝에 두 층 추가 한다.
- 하이퍼파라미터를 설정한다. 필터 수, 커널 크기, 패딩 등.
처음부터 시행착오를 되풀이하지 말고 관련 연구 문헌을 참고해서 유효한 값을 알아보자.
다음 내용은 꼭 숙지하시기 바랍니다.
- CNN을 구성하는 주요 층의 동작 원리(합성곱층, 풀링층, 전결합층, 드롭아웃층)와 필요한 이유
- 하이퍼파라미터의 의미(필터 수, 커널 크기, 스트라이드, 패딩 등)
- 원하는 신경망 구조를 구현하는 방법
이번 게시물에선 AlexNet의 간략 버전을 실제로 구현해서 데이터셋을 학습해보겠습니다.
AlexNet은 5개의 합성곱층과 풀링층, 3개의 전결합층으로 구성되어 있습니다.
간략 버전은 다음과 같습니다.
CNN: INPUT -> CONV_1 -> POOL_1 -> CONV_2 -> POOL_2 -> CONV_3 -> POOL_3 -> DO -> FC -> DO -> FC(softmax)
모든 은닉층의 활성화 함수는 ReLU를 사용합니다.
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
model = Sequential()
model.add(Conv2D(filters=16, kernel_size=2, padding='same', activation='relu',
input_shape=(32, 32, 3)))
model.add(MaxPooling2D(pool_size=2))
model.add(Conv2D(filters=32, kernel_size=2, padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=2))
model.add(Conv2D(filters=64, kernel_size=2, padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=2))
model.add(Dropout(0.3))
model.add(Flatten())
model.add(Dense(500, activation='relu'))
model.add(Dropout(0.4))
model.add(Dense(10, activation='softmax'))
model.summary()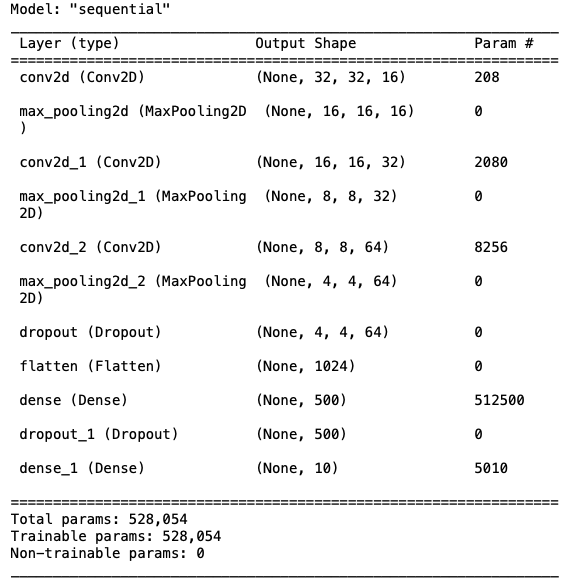
4단계: 모델 컴파일 하기
모델의 학습을 시작하기 전에 마지막으로 손실 함수, 최적화 알고리즘, 학습 과정 모니터링에 사용할 평가 지표 등 세 가지 하이퍼파라미터를 정해야 합니다.
- 손실 함수: 학습 데이터를 대상으로 신경망의 성능을 파악하는 측정 수단
- 최적화 알고리즘: 손실값이 최소가 되도록 파라이터(가중치와 편향)를 최적화하기 위해 사용할 알고리즘. 대부분 확률적 경사 기법을 사용함
- 평가 지표: 학습 및 테스트 과정에서 사용할 모델의 평가 지표. 여기서는 정확도를 의미하는 metrics=['accuracy']를 사용한다.
다음 코드로 정의가 끝난 모델을 컴파일할 수 있습니다.
# compile the model
model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
5단계: 모델 학습하기
신경망을 학습할 준비가 모두 끝났습니다.
케라스 라이브러리로 구현한 모델은 .fit() 메서드만 호출하면 학습이 진행됩니다.
학습 데이터에 모델을 부합시킨다는 의미입니다.
from keras.callbacks import ModelCheckpoint
# train the model
checkpointer = ModelCheckpoint(filepath='model.weights.best.hdf5', verbose=1, save_best_only=True)
hist = model.fit(x_train, y_train, batch_size=32, epochs=100,
validation_data=(x_valid, y_valid), callbacks=[checkpointer],
verbose=2, shuffle=True)
학습 중 출력된 메시지를 보면 신경망의 대략적인 성능과 함께 어떤 하이퍼파라미터를 조정해야 하는지 알 수 있습니다.

이는 다음 게시물에서 설명하겠습니다.
지금은 다음 내용만 숙지하도록 합시다.
- loss와 acc는 각각 학습 데이터에 대한 오차와 정확도를 의미한다. val_loss와 val_acc는 검증 데이터에 대한 오차와 정확도다.
- 한 에포크가 끝날 때마다 val_loss와 val_acc의 변화를 주시하라. loss는 감소하고 acc가 증가하고 있다면 에포크 마다 학습이 잘 진행되고 있는 것이다.
- 처음 3에포크 동안은 매 애포크마다 가중치를 저장했다. 그 이유는 검증 데이터에 대한 손실값이 개선되어 있었기 때문이다. 이와 같이 가장 성능이 좋았던 가중치는 해당 에포크가 끝나면 저장된다.
- 4에포크에서 loss가 증가했는데 이때 학습을 종료하면, 그때까지의 학습 과정에서 가장 성능이 좋았던 3에포크의 가중치를 사용한다.
- val_loss가 진동하면 하이퍼파라이터를 조절할 필요가 있다.
0.8 0.9 0.7 1.0처럼 움직이면, 학습률이 너무 커서 오차 함수의 경사를 내려가지 못할 가능성을 고려해야 한다. - val_loss가 감소하지 않으면(과소적합) 모델이 데이터에 비해 너무 단순해서 과소적합을 일으켰을 가능성이 높다. 은닉층을 추가해 모델의 복잡도를 확보하여 모델이 데이터에 부합될 수 있게 해야 한다.
- loss는 감소, val_loss가 정체되면, 훈련 데이터에 과적합이 발생했다는 신호다. 이런 경우 드롭아웃층 등 과적합을 방지할 수단을 적용해야 한다.
6단계:val_acc가 가장 좋았던 모델 사용하기
저장된 가장 성능이 좋았던 가중치를 읽어옵니다.
# load the weights that yielded the best validation accuracy
model.load_weights('model.weights.best.hdf5')
7단계: 모델 평가하기
모델을 평가하고 정확도를 계산해서 모델이 이미지 분류를 올바르게 예측하는 빈도를 나타내는 백분율을 계산합니다.
# evaluate and print test accuracy
score = model.evaluate(x_test, y_test, verbose=0)
print('\n', 'Test accuracy:', score[1])
해당 코드를 실행하면 70% 정도의 정확도를 얻을 수 있습니다.
CNN 구조에 층을 추가해 보며 성능이 어떻게 변화하는지 살펴볼 수 있습니다.
다음 장에서는 딥러닝 프로젝트를 시작하는 방법과 모델의 성능 개선을 위한 하이퍼파라미터 튜닝을 다뤄보겠습니다.
이때 해당 예제를 다시 보며 성능을 높여보려 합니다.
'Study > Vision & Deep Learning' 카테고리의 다른 글
| [VISION] 비전 시스템을 위한 딥러닝(7) - R-CNN, SSD, YOLO를 이용한 사물 탐지 (1) | 2023.05.31 |
|---|---|
| [VISION] 비전 시스템을 위한 딥러닝(6) - 전이학습 (0) | 2023.05.30 |
| [VISION] 비전 시스템을 위한 딥러닝(4) - 프로젝트: 이미지 분류 정확도 개선하기 (0) | 2023.05.29 |
| [VISION] 비전 시스템을 위한 딥러닝(3) - 딥러닝 프로젝트 시동걸기 (0) | 2023.05.29 |
| [VISION] 비전 시스템을 위한 딥러닝(1) - 합성곱 신경망 (2) | 2023.05.28 |