해당 게시물에서는 머신러닝 프로젝트를 시작하고 마치는 전체 과정을 다뤄본다.
빠르고 효율적으로 동작하는 딥러닝 시스템을 만드는 방법과 결과를 분석하고 성능을 개선하는 방법도 살펴본다.
Check Points
- 어떤 신경망 구조로 시작할 것인가?
- 은닉층 수는?
- 각 층의 유닛 또는 필터 수는?
- 학습률은 얼마로?
- 어떤 활성화 함수 사용?
- 데이터 수집과 하이퍼파라미터 튜닝 중 모델 성능 개선에 도움이 될까?
4.1 성능 지표란
모델 성능을 평가하는 가장 간단한 수단은 정확도다.
정확도 = 정답을 맞힌 횟수 / 전체 표본 수
4.1.1 정확도가 가장 좋은 지표인가
희귀한 질환의 유무를 판정하는 진단 모델을 설계한다고 해보자.
해당 질환은 1백만 명 중 1명꼴로 발생한다.
음성을 진단하는 시스템이 99.9999% 정확도를 갖게 된다고 하면 좋은 예측기 일까?
결과적으로 이는 양성을 맞추지 못하기 때문에 해당 모델의 성능을 평가하기 좋은 지표가 아니다.
4.1.2 혼동 행렬 (Confusion matrix)
혼동 행렬은 모델의 분류 결과를 정리한 표다.
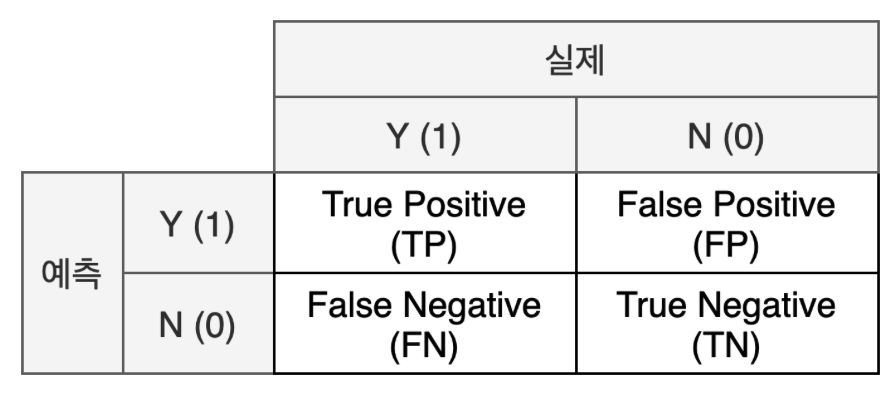
- TP: 모델이 양성을 정확히 예측
- TN: 모델이 음성을 정확히 예측
- FP: 실제 음성이지만 모델이 양성이라고 잘못 예측. 1종 오류라고도 한다.
- FN: 실제 양성이지만 모델이 음성이라고 잘못 예측. 2종 오류라고도 한다.
병을 예측하는 프로그램에서 어떤 오류가 더 치명적일까?
실수로 없는 질환을 판정해 추가 검사를 받는 편이 더 안전할 것이다. 반대로 실제 양성인데 놓치는 경우엔 치명적일 것이다.
이럴 경우 FN을 더 중요하게 다뤄야 한다.
4.1.3 정밀도와 재현율
재현율(recall or 민감도 sensitivity)은 모델이 질환이 있는 사람을 얼마나 잘못 진단했는지 알려준다.
재현율은 질환이 있는 사람을 음성으로 진단한 위음성이 얼마나 되는지 나타내는 지표이다.
재현율 = 진양성 TP / (진양성 TP + 위음성 FN)
정미로(precision or 특이성 specificity)는 재현율의 반대 개념이다. 모델이 질환이 없는 사람을 얼마나 잘못 진단했는지 알려준다.
다시 말해 위양성이 얼마나 되는지 나타내는 지표다.
정밀도 = 진양성 TP / (진양성 TP + 위양성 FP)
4.1.4 F-점수
재현율(r)과 정밀도(p)를 단일 지표로 한꺼번에 나타내고 싶을 경우도 있다. 이때 F-점수를 사용한다.
F-점수는 정밀도와 재현율의 조화평균으로 정의된다.
F-점수 = 2pr / (p + r)
질환 판정 모델을 다시 살펴보면, 해당 모델은 재현율이 더 중요한 모델이다.
만약, 위음성 판정이 거의 없어 재현율을 충분히 확보했지만, 위양성 건수가 많아 정밀도가 낮다면?
불필요한 검사가 늘어났다는 뜻이기 때문에 덜 중요해도 함께 봐야 한다.

4.2 베이스라인 모델 설정하기
당명한 문제의 종류에 따라 신경망 구조에 맞는 베이스라인을 설정해야 한다.
베이스라인 모델은 다음과 같은 사항을 고려해서 설정한다.
- 어떤 유형의 신경망? MLP, CNN, RNN
- YOLO나 SDD 등의 물체 인식 기법을 적용해야 하나?
- 신경망의 층수는?
- 활성화 함수는?
- 최적화 알고리즘은?
- 드롭아웃, 배치 정규화 등 규제화 기법을 사용해 과적합을 방지해야 하는가?
이미 연구가 많이 진행된 주제라며 기존 연구를 답습하는 것이 좋다.
모델을 처음부터 학습하지 않고 다른 데이터셋으로 이미 학습된 모델을 가져와서 사용하는 방법도 있는데, 이런 방법을 전이학습이라고 한다.
4.3 학습 데이터 준비하기
여기서는 학습을 시작하기 전에 필요한 기본적인 데이터 준비 기법을 다룬다.
4.3.1 훈련 데이터, 검증 데이터, 테스트 데이터로 분할하기
이때 가장 중요한 원칙은 테스트 데이터를 학습에 사용해서는 안 되는 점이다.
1) 검증 데이터란
테스트 데이터는 학습이 완료된 후 최종 성능을 측정하는 목적으로만 사용해야 한다.
따라서 훈련 데이터를 다시 분할한 별도의 데이터셋을 이용해서 학습 중 파라미터를 튜닝하는데, 이 데이터셋을 검증 데이터라고 한다.
모델 학습이 끝난 후 최종 성능 측정은 테스트 데이터를 대상으로 한다.
2) 훈련 데이터, 검증 데이터, 테스트 데이터를 잘 분할하는 방법
전통적으로 훈련 데이터와 테스트 데이터의 비중은 8:2, 7:3 비율을 많이 사용한다.
검증 데이터를 추가해야 한다면 6:2:2, 7:1.5:1.5의 비율을 많이 사용한다.
하지만, 이들은 데이터셋의 규모가 수만 개 밖에 없던 시절 사용되던 기준이다.
최근에는 훨씬 거대한 규모의 데이터셋을 사용하므로 검증과 테스트 데이터는 전체의 1%로도 충분한 경우가 있다.
데이터를 분할할 때 주의할 점은 분할된 훈련, 검증, 테스트 데이터가 모두 같은 분포를 따라야 한다는 것이다.
고해상도로만 훈련한 모델은 저해상도를 일반화하지 못한다.
4.3.2 데이터 전처리
전처리 기법은 여러 가지가 있고, 학습에 사용할 데이터셋의 상태나 문제의 유형에 따라 적절히 선택한다.
다행히 신경망은 그리 복잡한 전처리를 필요로 하지 않는다.
1) 회색조 이미지 변환
색상 정보가 필요 없거나 학습의 계산 복잡도를 경감시켜야 한다면, 이미지를 회색조로 변환하는 것도 검토해 볼 만하다.
2) 이미지 \크기 조절
신경망의 한계점 중 하나는 입력되는 모든 이미지의 크기가 같아야 한다는 것이다.
예를 들어 MLP를 사용하면 입력층의 노드 수가 이미지의 픽셀 수와 같아야 한다.
CNN 역시 첫 번째 합성곱층의 입력 크기를 이미지 크기에 맞춰 설정해야 한다.
3) 데이터 정규화
데이터 정규화란 데이터에 포함된 입력 특징(이미지의 경우 픽셀값)의 배율을 조정해서 비슷한 분포를 갖게 하는 것이다.
정규화가 반드시 필요하지는 않지만 모든 이미지의 픽셀값 범위를 동일하게 조정하면 학습된 모델의 성능이 개선되거나 학습 시간이 짧아지는 장점이 있다.
값은 작게 값의 범위는 동일하게
-> 모든 픽셀값의 평균과 표준편차를 구한 다음 각 픽셀값에서 이 평균을 빼고 표준편차로 나누는 방법으로 두 조건을 만족시킬 수 있다.
이를 통해 손실함수의 모양이 대칭성을 키워 경사 하강법 알고리즘이 전역 최소점에 빠르게 도달할 수 있다.
정규화되지 않은 특징은 각 특징마다 값의 배율이 다르기 때문에 경사 하강법으로 계산한 손실 함수의 경사가 가파른 방향이 매번 변경되기 때문에 오래 걸리고 진동한다.
4) 데이터 강화
뒤에 규제화를 설명할 때 자세히 다루겠다.
데이터 강화를 데이터 전처리로도 활용할 수 있다는 점을 기억하기 바란다.
4.4 모델을 평가하고 성능 지표 해석하기
신경망이 비판받는 큰 이유 중 하나는 내부 동작이 블랙박스라는 점이다.
해당 절에서는 신경망 모델을 진단하고 동작을 분석하는 방법을 설명한다.
4.4.1 과적합의 징후
모델의 학습이 끝나면, 모델에 존재하는 병목이 성능에 영향을 미치는지 확인하고 개선이 필요한 부분을 찾는다.
대부분 과적합 또는 과소적합 때문이다.
1) 과소적합
모델의 표현력이 데이터에 비해 부족해서 생긴다.
대표적으로 단일 퍼셉트론을 사용해서 데이터를 분류하는 경우를 들 수 있다.
훈련 데이터에 대한 성능이 낮다면 과소적합을 일으키고 있을 가능성이 높다.
신경망에 은닉층을 추가하거나 에포크 수를 늘리거나, 다른 신경망 구조를 사용해야 한다.
2) 과적합
모델이 지나치게 복잡한 경우 발생한다.
훈련 데이터 자체를 기억하는 현상이고 일반화 성능이 낮다.
훈련 데이터에 대한 성능은 높은데 검증 데이터에 대한 성능이 상대적으로 낮다면 과적합을 일으키고 있을 가능성이 높다.
이런 경우에는 시행착오를 거치며 적절한 성능이 나올 때까지 하이퍼파라미터를 조정해야 한다.
3) 베이즈 오차율
이론적으로 모델이 실현 가능한 갖아 좋은 성능을 의미한다.
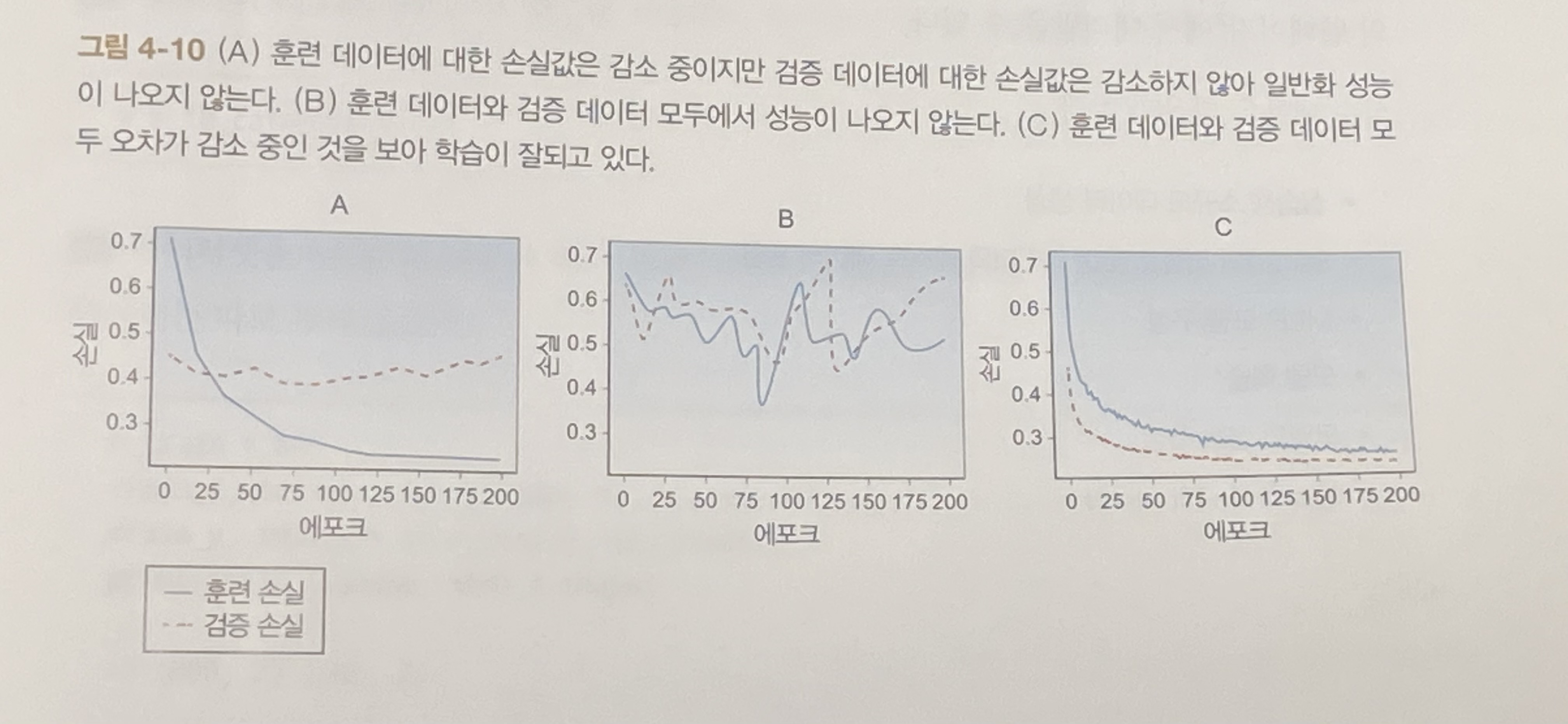
4.4.2 학습 곡선 그리기
훈련 데이터와 검증 데이터에 대한 손실률 변화 추이를 그래프로 보면 성능을 보다 직관적으로 이해할 수 있다.
4.4.3 실습: 신경망의 구성 학습, 평가
하이퍼파라미터 튜닝에 들어가기 전에 데이터 분할과 모델 구성, 학습, 성능 측정 결과의 시각화 과정을 빠르게 경험해 보자.
1) 의존 모듈 임포트 하기
# import dependencies
from keras import backend as K
from sklearn.datasets import make_blobs # 사이킷런 라이브러리를 이용해 예제 데이터 생성
from keras.utils import to_categorical # 클래스 벡터를 바이너리 클래스 행렬(원-핫 인코딩)로 변환하는 케라스 함수
from keras.models import Sequential # 신경망 및 층을 구현한 라이브러리
from keras.layers import Dense
from matplotlib import pyplot # 시각화용 라이브러리
2) 사이킷런의 make_blils 함수를 사용해서 특징과 분류 클래스가 각각 2개인 실습용 소규모 데이터셋 생성
# generate a toy dataset of only two features and four label classes
X, y = make_blobs(n_samples=1000, centers=4, n_features=2, cluster_std=2, random_state=2)
3) 케라스의 to_catgorical 함수를 사용해서 레이블에 원-핫 인코딩을 적용한다.
# one-hot encode output variable
y = to_categorical(y)
4) 데이터셋을 80:20의 비율을 따라 훈련과 테스트 데이터로 분류한다. 편의상 검증 데이터는 생략한다.
n_train = 800
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]
print(trainX.shape, testX.shape)
5) 모델을 구성한다. 층이 2개인 MLP를 사용한다.
# develop the baseline model architecture
# here we are building a very simple, two-layer network
model = Sequential()
# 입력 특징이 2개이므로 입력 차원이 2이다.
model.add(Dense(25, input_dim=2, activation='relu'))
# 분류 대상 클래스가 네 가지 이므로 출력층의 노드는 4개다.
model.add(Dense(4, activation='softmax')) # four hidden units because we have 4 label classes
# 손실 함수는 교차 엔트로피, 최적화 알고리즘은 ADAM을 사용한다. (4.7.2절 참조)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()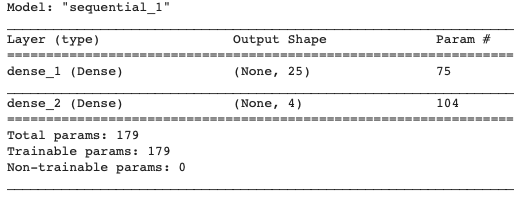
6) 1,000 에포크 동안 모델 학습
# train the model
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=1000, verbose=1)
7) 모델 성능 평가
# evaluate the model
_, train_acc = model.evaluate(trainX, trainy, verbose=0)
_, test_acc = model.evaluate(testX, testy, verbose=0)
print('Train: %.3f, Test: %.3f' % (train_acc, test_acc))
9) 정확도를 기준으로 모델의 학습 곡선을 그린다.
# plot learning curves of model accuracy
pyplot.plot(history.history['accuracy'], label='train')
pyplot.plot(history.history['val_accuracy'], label='test')
pyplot.legend()
pyplot.show()
해당 신경망의 성능을 평가하면, 훈련과 테스트 데이터가 모두 비슷한 성능을 보이며 학습이 진행된 것을 볼 수 있다.
이 정도의 간단한 소규모 데이터 셋에서 정확도가 85%라는 것은 그리 좋은 성능은 아니다.
이 신경망의 성능을 개선하기 위해 모델의 복잡도를 높여 과소적합을 방지한다.
4.5 신경망을 개선하고 하이퍼파라미터 튜닝하기
학습을 마친 뒤 하이퍼파라미터 조정, 데이터 전처리, 데이터 추가 수집 중 무엇을 해야 할지 선택해야 한다.
하이퍼파라미터 조정에 들어가기 전 먼저 데이터 수집이 더 필요한지 판단해야 한다.
4.5.1 데이터 추가 수집 또는 하이퍼파라미터 튜닝
데이터 레이블링을 자동화하려는 여러 연구가 진행 중이지만 집필 시점에 대부분의 레이블링 작업은 수동으로 이뤄지고 있다.
이 때문에 데이터의 추가 수집은 큰 비용을 수반할 수 있다.
물론 학습 알고리즘을 개선하는 것보다 데이터를 추가 수집하는 편이 훨씬 나은 상황도 있다.
다음과 같은 기준을 따른다.
- 훈련 데이터에 대한 기존 성능이 납득할만한 수준인지 확인한다.
- 훈련 데이터 정확도와 검증 데이터 정확도 두 지표를 시각화해서 관찰한다.
- 훈련 데이터에 대한 성능이 낮다면 과소적합 가능성. 과소적합은 기존 데이터도 충분히 활용하지 못하는 상황이므로 데이터 수집 불필요. -> 하이퍼파라미터 조정 혹은 기존 훈련 데이터 클린징!
- 훈련 데이터에 대한 성능은 괜찮고, 테스트 데이터에 대한 성능이 떨어진다면 과적합 가능성. 데이터 추가 수집이 유효하다.
4.5.2 파라미터와 하이퍼파라미터
파라미터는 가중치와 편향을 통틀어 이르는 말로 신경망의 학습 대상.
하이퍼파라미터는 학습률, 배치 크기, 에포크 수, 은닉층 수 등이 있다.
4.5.4 신경망의 하이퍼파라미터
하이퍼파라미터 튜닝의 어려운 점은 모든 상황에 유효한 값이 없다는 점이다.
신경망의 하이퍼파라미터는 크게 다음 세 가지로 분류할 수 있다.
- 신경망 구조
- 은닉층 수 (신경망의 깊이)
- 각 층의 뉴런 수 (층의 폭)
- 활성화 함수의 종류 - 학습 및 최적화
- 학습률과 학습률 감쇠 유형
- 미니배치 크기
- 에포크 수 (조기 종료 적용 여부 포함) - 규제화 및 과적합 방지 기법
- L2 규제화
- 드롭아웃층
- 데이터 강화
4.5.4 신경망 구조
신경망 구조를 정의하는 하이퍼파라미터를 살펴보자.
1) 신경망의 깊이와 폭
신경망의 규모가 작으면 과소적합이 발생하기 쉬우며, 반대의 경우 과적합이 발생할 수 있다.
데이터셋이 복잡할수록 그 특징을 학습하기 위해 신경망의 학습 능력이 더 많이 필요하다.
일반적으로는 검증 데이터의 오차가 더 이상 개선되지 않을 때까지 은닉층의 뉴런을 계속 추가해도 된다.
신경망의 유닛 수가 너무 적으면 과소적합이 발생하기 쉽다. 절절히 규제화를 적용한다면 뉴런을 추가해도 성능 저하는 발생하지 않는다.
텐서플로 샌드박스에서 다양한 시도를 해보며 감각을 기르는 것을 추천한다.
(https://playground.tensorflow.org)
2) 활성화 함수의 종류
활성화 함수는 뉴런에 비선형을 도입하는 수단이다. 활성화 함수가 없다면 뉴런에서 일어나는 계산은 선형 조합(가중치 합계)에 지나지 않는다.
연구가 활발한 분야이며 은닉층에 ReLU와 누설 ReLU 등이 성능이 좋다고 알려져 있다.
3) 층과 파라미터
은닉층 수와 유닛 수를 결정할 때 신경망의 파라미터 수와 그에 따른 계산 복잡도를 함께 고려하면 도움이 된다.
신경망의 뉴런이 많아질수록 학습 시 최적화해야 할 파라미터 수가 늘어난다.
학습 시 사용할 하드웨어를 고려해서 파라미터 수의 증감을 결정한다. 파라미터 수를 줄이는 방법은 다음과 같다.
- 신경망의 층수와 폭을 감소시킨다.
- 풀링층을 추가하거나 합성곱층의 스트라이드 또는 패딩 설정을 조정해서 특징 맵의 크리를 줄인다.
4.6 학습 및 최적화
신경망 구조를 확정했으니 학습과 최적화 과정에 관여하는 하이퍼파라미터를 살펴보자.
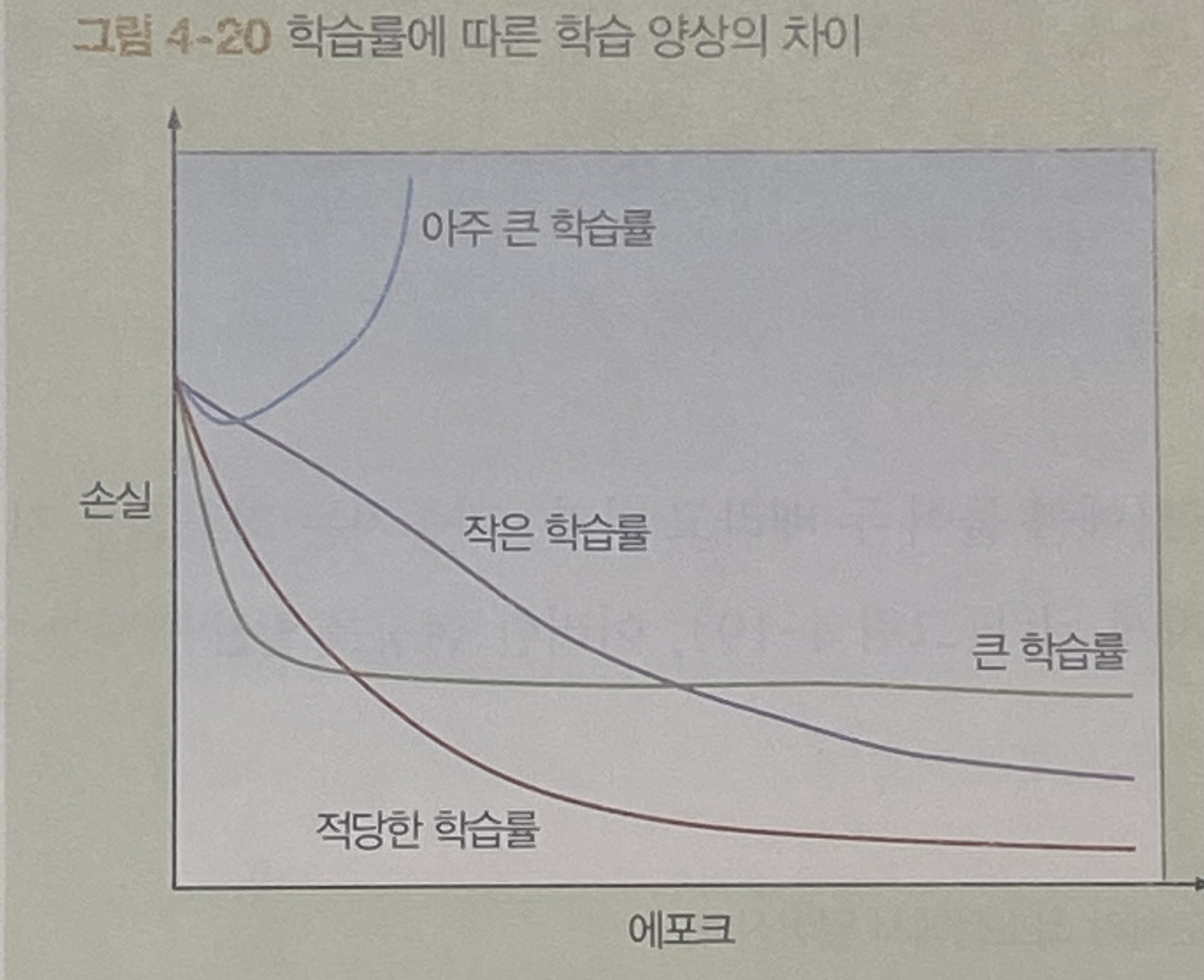
4.6.1 학습률과 학습률 감쇠 유형
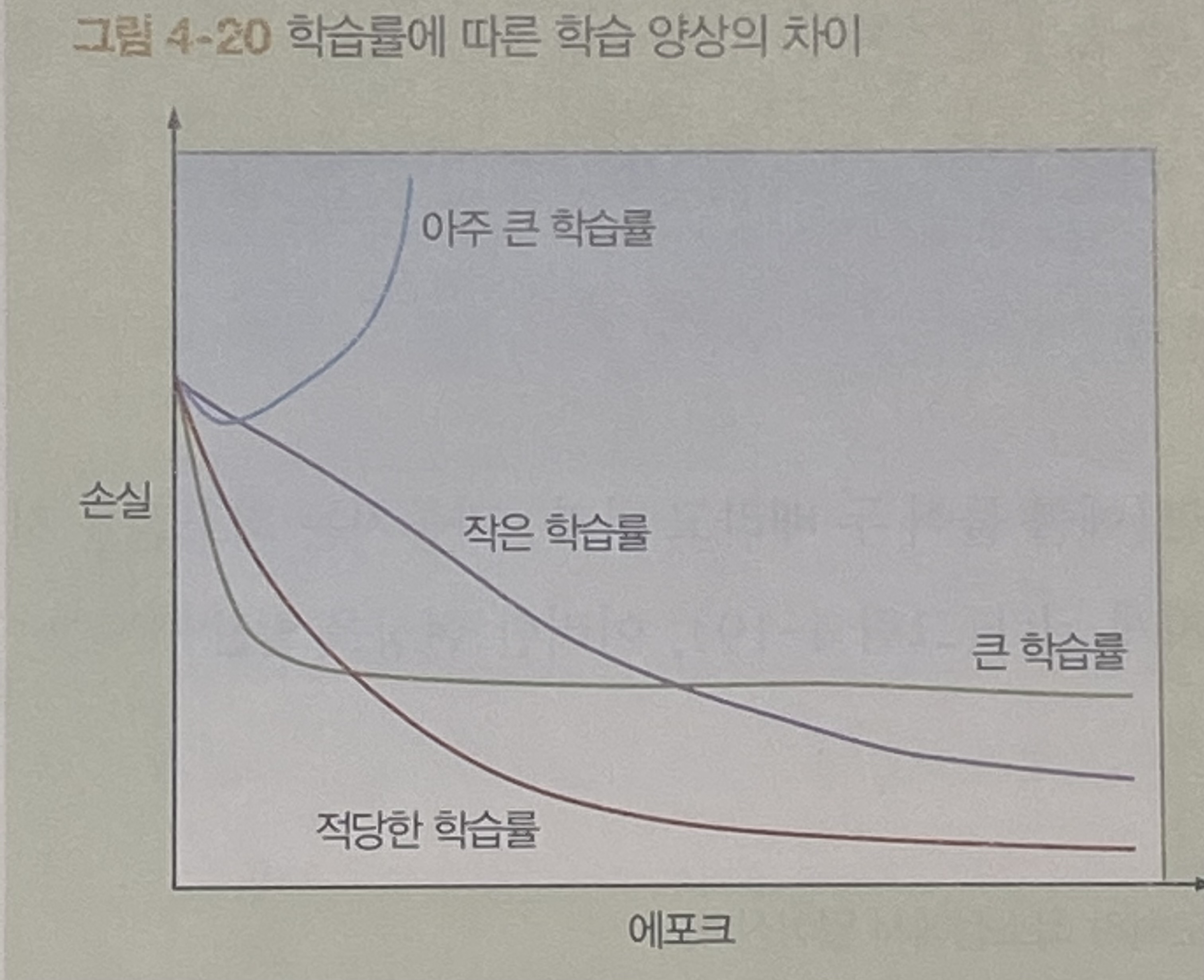
경사 하강법을 사용해 최적화를 진행할 때 학습률은 오차 함수의 경사를 어느 정도의 보폭으로 내려갈지 결정하는 변수이다.
경사 하강법은 경사(편미분)를 계산해서 오차가 가장 크게 줄어드는 방향을 결정한다.
이상적인 학습률은 한 번만에 최소점에 도달할 수 있는 수치이다.
학습률이 이상적인 값보다 작다면 경사를 내려가며 최소점에 도달하고, 이론적으로 훨씬 작아도 오래 걸리지만 도달한다.
이상적인 값보다 크다면 지나쳐 버릴 것이다. 만약, 훨씬 크다면 최소점을 지나쳐 원래보다 멀어지게 되고, 이러한 현상을 발산이라고 한다.
4.6.2 최적의 학습률을 정하는 방법
최적의 학습률은 손실 함수의 모양에 따라 달라진다.
손실 함수의 모양은 다시 모델의 구조와 데이터셋에 의해 결정된다.
케라스, 텐서플로, 파이토치 등 모든 딥러닝 라이브러리에서 기본 값으로 미리 설정된 학습률은 괜찮은 출발점 역할을 한다.
모델의 학습이 잘되지 않는다면, 0.1, 0.01, 0.001 등의 값으로 조절하며 성능과 학습 시간을 관찰해서 최적의 값을 찾는다.
- 파라미터가 수정될 때마다 val_loss가 감소하면 정상. 개선이 멈출 때까지 학습
- 학습이 끝났는데 val_loss가 계속 감소라면 학습률이 너무 작아 파라미터가 수렴하지 못한 것
1) 학습률을 두고 에포크를 늘린다.
2) 학습률을 조금 증가시킨다. - val_loss가 증갑을 반복하며 진동하면 너무 큰 것. 학습률 감소
4.6.3 학습률 감쇠와 적응형 학습
고정된 학습률을 사용하지 않고 학습률 감쇠를 적용하는 방법도 있다. 이는 학습을 진행하는 도중에 학습률을 변화시키는 방법이다.
대부분의 경우 고정된 학습률 보다 성능이 뛰어나다.
학습 초기엔 큰 값을 적용하고 학습이 진행됨에 따라 학습률을 감소시킨다.
학습률 감쇠에도 여러 가지 종류가 있는데 일정 비율로 학습률을 감소시키는 계단형 감쇠가 대표적이다.
또 다른 방법으로는 지수 감쇠가 있다. 계단 감쇠보다는 오래 걸리지만 수렴할 수 있다.
이 외에도 적응형 학습이 있다. 적응형 학습은 학습의 진행이 멈추는 시점에 학습률을 경험적으로 설정된 값만큼 자동으로 수정하는 방식이다. 학습 속도가 지나치게 느려지는 등 상황에 따라서 증가하기도 한다.
적응형 학습은 일반적인 학습률 감쇠 기법보다 높은 성능을 보이며 Adam과 Adagrad가 적응형 학습이 적용된 최적화 알고리즘이다.
4.6.4 미니배치 크기
batch_size는 특히 학습 중 필요한 리소스 요구 사항과 학습 속도에 큰 영향을 미친다.
- 배치 경사 하강법 BGD:
데이터셋 전체를 한 번에 신경망에 입력, 가중치 수정은 한 에포크에 한 번만 일어난다. 장점은 노이즈가 적고 최소점까지 큰 보폭으로 접근할 수 있다. 단점은 가중치 한 번 수정하는 데 걸리는 시간이 오래 걸린다. 소규모에 유리! - 확률적 경사 하강법 SGD or 온라인 학습:
훈련 데이터를 한 번에 하나씩 신경망에 입력해서 가중치르 수정한다. SGD는 데이터 하나마다 가중치가 수정된다. 따라서 가중치의 진행 방향에 진동이 심하며 때로는 엉뚱한 방향으로 나아가기도 한다. 이러한 노이즈는 학습률을 감소시켜 억제할 수 있고, 대체로 BGD 보다 나은 성능을 보인다. 전역 최소점에 빠르고 더 가까이 접근 가능하기만, 데이터 여러 개를 한 번의 행렬 연산을 처리하는 이점을 살리지 못한다. (한 번에 하나만 처리) - 미니배치 경사 하강법: 배치 경사 하강법과 확률적 경사 하강법의 중간에 해당한다. 이 방법을 통해 행렬곱을 이용한 계산 속도가 향상되고, 전체 데이터셋을 사용하지 않아 가중치를 한 번 수정하는 데 걸리는 시간 역시 짧아진다.
데이터 셋의 크기가 작다면(<= 2000) BGD를 사용해도 빠른 시간 안에 학습이 가능하다.
그게 아니라면, 미니배치의 크기를 두 배씩 늘려간다. 64 또는 128개로 시작하는 것이 좋다.
1024 이상의 미니배치는 잘 사용되지 않는다. 미니배치의 수를 크게 하면 행렬곱을 이용한 계산 속도 향상 효과를 볼 수 있지만, 학습에 필요한 메모리 용량이 증가한다.
4.7 최적화 알고리즘
학습률 조정은 단순한 방법으로 적절한 값으로 선정하기 어렵다. 따라서 경사 하강법을 더 개선하려면 좀 더 기발한 방법이 필요하다.
다음으로 두 가지 대표적인 성능이 좋은 최적화 알고리즘에 대한 설명을 해보겠다.
4.7.1 모멘텀을 적용한 경사 하강법
확률적 경사 하강법은 오차의 최소점으로 향하면서 진동하기 때문에 학습률을 큰 값으로 설정할 수 없었다.
가중치 이동 방향의 이러한 진동을 감소시키기 위해 모멘텀이 고안되었다. 모멘텀은 엉뚱한 방향으로 가중치가 이동하는 것을 완화시키는 기법이다.
쉽게 설명하면 진동의 세로 방향으로는 학습을 느리게 하고, 가로는 빠르게 진행한다. (가중치가 세로 방향으로 진동하며 가로 방향의 최적점을 향해 나아간다고 가정한다.)
- 기존 가중치 수정식
-> Wnew = Wold - 학습률 x 경사 - 수정된 가중치 수정식
-> Wnew = Wold - 학습률 x 경사 + 속도
4.7.2 Adam
Adam은 적응형 모멘트 예측(adaptive moment estimation)의 약자이다.
Adam은 모멘텀과 비슷하게 이전에 계산했던 경사의 평균을 속도항으로 사용하지만, 속도항이 지수적으로 감쇠된다는 차이가 있다.
모멘텀이 경사를 굴러 내려가는 공과 같다면, Adam은 무거운 공이 마찰력을 가진 바닥을 굴러가며 모멘텀이 감소하는 것에 비유할 수 있다.
다른 최적화 알고리즘에 비해 학습 시간이 빠르다.
Adam 작성자는 다음과 같은 기본값을 제안한다.
- 학습률은 조정 필요
- 모멘텀항 B1은 0.9를 많이 사용
- RMSprop 항 B2는 0.999를 많이 사용
- e는 10^(-8)로 설정
4.7.3 에포크 수와 조기 종료 조건
에포크는 학습 진행 중 전체 훈련 데이터가 한번 모델에 노출된 횟수를 의미한다. 즉, 신경망의 반복 학습 횟수이다.
반복 학습 횟수가 많을수록 신경망이 더 많은 특징을 학습할 수 있다.
횟수가 충분한지 확인하는 가장 직관적인 기준은 오차값이 감소하는 한 학습을 계속하는 것이다.
이때, 훈련 오차와 검증 오차가 함께 개선되다가 검증 오차가 증가하면서 과적합의 징후가 나타나면, 조기 종료 할 수 있다.
4.7.4 조기 종료
조기 종료는 과적합이 발생하기 전에 조기에 학습을 종료하는 알고리즘이다.
검증 오차를 주시하다가 검증 오차가 증가하기 시작하면 학습을 중지하는 방법이다.
케라스 함수는 다음과 같다.
EarlyStopping(monitor='val_loss', min_delta = 0, patience = 20)
인수는 다음과 같다.
- monitor :
학습 중 주시할 지표. - min_delta :
주시 중인 지표가 개선 중인지에 대한 기준이 되는 상승폭을 지정한다. 해당 변수에는 표준값이 없다.
min_delta 값을 정하려면 몇 에포크 동안 학습을 지켜보며 오차와 검증 데이터에 대한 정확도를 관찰한다. 그 변화율을 기준으로 min_delta 값을 정하는데 기본값인 0도 잘 동작한다. - patience :
과적합이 발생했다고 판단하는 기준으로 연속으로, 주시 중인 지표가 개선되지 않는 에포크 수를 의미한다.
약간 여유를 두는 편이 좋다. 잠시 정체되거나 진동하다 다시 개선하는 경우도 많기 때문! 10 에포크 이상 개선이 없으면 중단하는 편이 좋다.
4.8 과적합을 방지하기 위한 규제화 기법
과적합이 발생했다면 신경망의 표현력을 감소시켜야 한다. 가장 먼저 할 수 있는 방법이 규제화다.
가장 널리 사용되는 규제화 기법인 L2 규제화, 드롭아웃, 데이터 강화를 설명한다.
4.8.1 L2 규제화
해당 규제화의 기본 아이디어는 오차 함수에 규제화항을 추가하는 것이다. 이에 따라 은닉층 유닛의 가중치가 0에 가까워지고 모델의 표현력을 감소시키는데 도움이 된다.
오차함수new = 오차함수old + 규제화항
위와 같이 항을 추가한다.
오차 함수는 평균제곱오차, 교차 엔트로피 등 무엇이든 사용할 수 있다.
규제화항은 다음과 같다.

람다는 규제화 파라미터, m은 인스턴스 수, w는 가중치이다.
L2 규제화의 원리는 역전파 계산에서 가중치가 수정되는 원리를 기억해야 한다.
오차 함수의 경사에 학습률을 곱해 기존 가중치에서 해당 값을 빼서 가중치를 수정한다.
규제항에 의해 기존 함숫값이 더 커졌기 때문에, 함숫값의 변화량 또한 기존보다 크다.
따라서 편미분이 커지므로 기존 가중치에서 빼는 값이 작아져 새로운 가중치는 규제항이 없을 때보다 작아지게 된다.
L2 규제화는 가중치를 0을 향해 감소시키기 때문에 가중치 감쇠라고 하기도 한다.
model.add(Dense(units =. 6, kernel_regularizer=regularizers.l2(lambda), activation = 'relu'))
lambda 값은 직접 조정해야 하지만 기본값으로도 잘 동작하고, 과적합이 해소되지 않으면 증가시킨다.
4.8.2 드롭아웃층
이 또한 신경망의 복잡도를 낮춰 과적합을 방지하는 방법이다. 3장에서 자세히 설명했으며 매우 간단하다.
반복마다 전체 뉴런 중 미리 정해진 비율만큼의 뉴런을 해당 반복 회차 동안 비활성화 한다.
주로 0.3~0.5 사이의 값을 사용하고, 0.3에서 시작하여 과적합이 발생하면 비율을 올려 대응한다.
L2 규제화와 드롭아웃은 모드 뉴런의 효율을 떨어뜨려 신경망의 복잡도를 감소시키는 기법이다.
L2는 억제, 드롭아웃은 비활성화라는 차이점이 있다.
둘 모두 신경망을 보다 유연하고 강건하게 하며 과적합을 억제하는 효과가 있다.
4.8.3 데이터 강화
추가가 여의치 않을 땐 기존 데이터에 약간 변형을 가해 새로운 데이터를 만드는 것도 가능하다.
이러한 것을 데이터 강화라고 한다. 이미지 반전, 회전, 배율 조정, 발기 조절 등 다양한 변환 방법을 강화에 사용할 수 있다.
데이터 강화는 모델이 특징 학습 중 대상의 원래 모습에 대한 의존도를 낮춰준다는 의미에서 규제화 기법으로 취급되기도 한다.
from keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(horizontal_flip=True, vertical_flip=True)
datagen.fit(training_set) # 훈련 데이터로부터 새로운 데이터를 생성하는 데이터 강화 실행
4.9 배치 정규화
이 장 앞부분은 학습 속도를 개선하기 위한 데이터 정규화를 설명했다.
앞서 배운 정규화는 입력층에 이미지를 입력하기 위한 학습 데이터의 전처리에 집중되었다.
이미 추출된 특징을 정규화하면 은닉층도 마찬가지로 정규화의 도움을 받을 수 있다.
추출된 특징을 변화가 심하므로 정규화를 통해 신경망의 학습 속도와 유연성을 더욱 개선할 수 있다.
이런 기법을 배치 정규화 BN라고 한다.
4.9.1 공변량 시프트 문제
Covariate shift가 무엇인지 설명하기 전에 배치 정규화를 적용할 때 발생할 수 있는 문제를 살펴보자.
고양이 이미지를 판정하는 분류기에 흰 고양이만 훈련 데이터로 제공하면, 좋은 성능이 나오지 않을 것이다.
테스트 데이터의 분포가 훈련 데이터와 다르면 모델은 혼란을 일으킨다.
데이터셋 X를 레이블 y에 매핑하도록 모델을 학습한 후 X의 분포가 변화한 경우를 공변량 시프트라고 한다.
4.9.2 신경망에서 발생하는 공변량 시프트
4개의 층을 가진 MLP를 생각해 보자.
L2의 출력은 L2에서 추출된 특징이다. L3는 이 입력을 받아 레이블 y와 가장 가까운 y_hat에 매핑하려 한다.
이 과정에서 이전 층의 파라미터가 함께 개입한다.
L1의 파라미터가 변화하면 L2의 입력도 변화한다. 이 현상을 L3 관점에서 보면 L2의 출력이 항상 변화하게 된다.
결국 이 신경망에 공변량 시프트가 발생하고 있는 것이다.
배치 정규화는 은닉층의 출력값 분포의 변화를 억제해서 이어지는 층의 학습이 좀 더 안정되도록 돕는 역할을 한다.
유닛을 비활성화하거나 값을 변경시키지 않아, 평균과 분산은 변하지 않는다.
4.9.3 배치 정규화의 원리
배치 정규화는 각 층의 활성화 함수 앞에 다음 연산을 추가하는 방법이다.
- 입력의 평균을 0으로 조정
- 평균이 0으로 조정된 입력을 정규화
- 연산 결과의 배율 및 위치 조정
해당 기법을 적용하면 각 층의 입력이 최적의 배율과 평균으로 조정된다.

배치 정규화는 입력층뿐만 아니라 은닉층도 정규화의 장점을 누릴 수 있다는 아이디어에서 출발했다.
배치 정규화 덕분에 뒷층의 학습이 앞층의 학습 결과의 영향을 덜 받으므로 각 층마다 독립적인 학습이 가능하게 된다.
앞층의 출력이 항상 같은 평균과 분산을 갖게 되므로 뒷층의 관점에서 입력이 크게 흔들리지 않는 효과가 있다.
즉, 은닉층의 출력을 항상 표준 분포를 따르도록 강제하는 방법이며, r과 B가 제어한다.
다음 게시물에서 해당 정규화를 적용한 이미지 분류 정확도 개선 프로젝트를 설명하겠다.
'Study > Vision & Deep Learning' 카테고리의 다른 글
| [VISION] 비전 시스템을 위한 딥러닝(7) - R-CNN, SSD, YOLO를 이용한 사물 탐지 (1) | 2023.05.31 |
|---|---|
| [VISION] 비전 시스템을 위한 딥러닝(6) - 전이학습 (0) | 2023.05.30 |
| [VISION] 비전 시스템을 위한 딥러닝(4) - 프로젝트: 이미지 분류 정확도 개선하기 (0) | 2023.05.29 |
| [VISION] 비전 시스템을 위한 딥러닝(2) - 프로젝트: 컬러 이미지 분류 실습(CNN) (0) | 2023.05.29 |
| [VISION] 비전 시스템을 위한 딥러닝(1) - 합성곱 신경망 (2) | 2023.05.28 |