이진 트리에 대한 마지막 내용으로 이진 검색 트리를 함께 알아보겠습니다.
1. 이진 검색 트리를 사용하는 이유
이전에 공부했던 힙 트리의 문제점은 다음과 같습니다.
1). 임의의 데이터를 갖는 노드를 삭제할 경우: O(n)
2). 트리에서 특정 데이터를 갖는 노드 검색: O(n)
다시 말해서 최악의 경우 위의 일을 처리할 때 모든 노드를 한번씩 다 거쳐야 합니다.
노드의 수가 적을 때는 큰 상관이 없지만, 노드의 수가 커지면 커질 수록 시간 복잡도가 크게 증가하는 단점을 가지고 있습니다.
이와 같은 문제점을 해결하기 위해 나온 알고리즘이 이진 검색 트리 입니다.
2. 이진 검색 트리
이진 검색 트리의 특징은 다음과 같습니다.
1). 모든 노드는 유일한 키 값을 갖고 있다.
2). 왼쪽 서브 트리에 저장된 키 값 < 루트 노드의 키 값
3). 오른쪽 서브 트리에 저장된 키 값 > 루트 노드의 키 값
4). 트리 내의 모든 서브 트리는 이진 검색 트리이다.
가장 중요한 것은 키를 이용하여 데이터를 검색하기 때문에 키는 절대 중복되면 안 됩니다.
다른 트리에서 부모 노드와 자식 노드의 크기가 같아도 괜찮았던 것과는 차이점이 있습니다.

사실 굉장히 간단하고 최대 힙 트리와 비슷한 구조를 가지고 있습니다.
항상 부모 노드에 저장된 값을 기준으로 왼쪽 자식은 작은 값, 오른쪽 자식은 큰 값을 저장하면 됩니다.
제일 중요한 건 "중복이 절대 안 된다." 입니다.
3. 이진 검색 트리 구현
3-1. 이진 검색 트리 구성 함수
1) 이진 검색 트리의 ADT
Node *Init_Tree(void): 구조체를 초기화 합니다.
void Input_Data(Node **root, int data): 노드를 추가합니다.
Node *Search_Data(Node *root, int data): 원하는 데이터를 가진 노드를 찾습니다.
Node *Find_Suc(Node *root, int data): 원하는 데이터를 가진 노드의 중위 후행자를 반환합니다.
void Delete_Data(Node *root, int data): 특정 데이터를 가진 노드를 삭제합니다.
void Inorder_Traverse(Node *root): 중위 순회하며 트리를 출력합니다.
void Print_Tree(Node *root): Inorder_Traverse 함수를 포함합니다.
이진 검색 트리의 재밌는 특징 중 하나는
중위 순회하며 출력 했을 때 작은 수 부터 큰 수로 차례대로 출력되는 것입니다.
함수와 함께 확인해보겠습니다.
2) 이진 검색 트리의 구조체
노드의 기본 구조는 동일합니다.
typedef struct NODE{
int data;
struct NODE *left_child;
struct NODE *right_child;
} Node;
3) 구조체 초기화
새로 추가될 노드를 초기화 합니다.
Node *Init_Tree(void){
Node *tr = (Node *)malloc(sizeof(Node));
tr->data = 0;
tr->left_child= NULL;
tr->right_child = NULL;
return tr;
}
4) 노드 추가
첫 번째로 중요한 것은 추가되는 데이터가 기존 트리에 존재하지 않는 것입니다.
두 번째로 중요한 것은 데이터의 크기에 따라 위치를 결정하는 것입니다.
해당 함수는 main 함수에서 다음과 같이 사용합니다.
Node *root = NULL;
Node *tmp;
Input_Data(&root, 20); // 이중 포인터를 사용하기 때문에 구조체 포인터 root의 주소를 입력합니다.
이중 포인터에 대해 게시물에 첨부된 포인터에 관한 자료를 보시거나 이전 게시물 중 아래 링크의 게시물을 보시면 이해하실 때 도움이 될 겁니다.
2020/02/23 - [공부/c언어 자료구조] - [자료구조 C 언어] C 프로그래밍 기초 - 5 : 포인터 뿌시기 (Pointer)
2020/02/24 - [공부/c언어 자료구조] - [자료구조 C 언어] C 프로그래밍 기초 - 6 : 2차원 배열, 포인터 배열, 배열 포인터
2020/02/25 - [공부/c언어 자료구조] - [자료구조 C 언어] C 프로그래밍 기초 - 7 : 이중 포인터와 2차원 배열의 관계
void Input_Data(Node **root, int data){ // 이중 포인터 변수 root를 사용합니다.
// root에는 위의 분홍 박스에서 입력된 &root가 저장됩니다.
// *root == *(&root)이기 떄문에
// root 구조체 포인터 변수의 주소(&root)가 가리키는
// 메모리 내부 데이터(동적할당된 구조체 포인터 변수의 주소가 저장됨)를 참조할 수 있습니다.
// 빈 트리인 경우 *root == NULL 입니다.
// 트리에 데이터가 있는 경우, *root == (동적할당된 구조체 포인터 변수의 주소)와 동일합니다.
// 따라서, **root == *(동적할당된 구조체 포인터 변수의 주소)이기 때문에
// **root는 구조체 내부의 멤버 변수를 참조할 수 있습니다.
// 이떄 (**root).data == (*root)->data와 동일합니다.
Node *rtmp;
Node *tmp = Init_Tree(); // 새롭게 추가될 노드를 만들어줍니다.
Node *cur = *root;
// 임의의 구조체 포인터 변수 *p에 대해
// 구조체 멤버 변수로의 접근은 (*p).data == p->data와 동일합니다.
// cur은 해당 개념을 확인하기 위해 사용됩니다.
tmp->data = data;
if(*root == NULL){ // 루트 노드가 비어있으면 루트 노드의 포인터 변수에 동적할당된 구조체 포인터 변수 tmp의 주소를 입력합니다.
*root = tmp;
}
else{ // 부모 노드와 새로 들어온 노드의 크기를 비교합니다.
if((*root)->data > data){ // 새로운 데이터가 작으면
if((*root)->left_child == NULL){ // 부모의 왼쪽 자식 노드가 되거나
(*root)->left_child = tmp;
}
else{
rtmp = (*root)->left_child; // 왼쪽 자식 노드가 차있으면, 부모노드가 왼쪽 자식 노드로 갱신되고
Input_Data(&rtmp, data); // 재귀 함수를 실행합니다.
}
}
else if(cur->data < data){ // 새로운 데이터가 크면
if(cur->right_child == NULL){ // 위의 과정이 반대로 진행됩니다.
cur->right_child = tmp;
}
else{
rtmp = cur->right_child;
Input_Data(&rtmp, data);
}
}
else{ // 부모 노드와 데이터가 같으면, 이미 저장된 데이터이기 때문에 노드를 추가하지 않습니다.
puts("The input data is already in Tree.\n");
}
}
}
5) 노드 검색
원하는 data를 가진 노드를 검색합니다.
이진 검색 트리를 사용하는 가장 큰 이유 중 하나입니다.
크기 순으로 좌/우로 정렬되어 있으므로 원하는 값과 동일한 값이 나올 때 까지 크기 비교를 하며 내려갑니다.
Node *Search_Data(Node *root, int data){
Node *cur;
Node *tmp = NULL;
cur = root;
pr = NULL; // 삭제 연산 시 사용하기 위해 검색한 노드의 부모 노드를 항상 저장해줍니다.
// 부모 노드는 전역 변수로 코드 초반에 선언됩니다.
while(cur != NULL){ // cur이 NULL이면 트리의 가장 아랫단까지 내려와도 찾는 데이터가 없는 경우입니다.
if(cur->data > data){
pr = cur;
cur = cur->left_child;
}
else if(cur->data < data){
pr = cur;
cur = cur->right_child;
}
else{
tmp = cur;
break;
}
}
return tmp;
}
6) 중위 후행자 탐색
스레드 이진 트리에서 공부 했던 insucc 함수를 응용한 함수입니다.
항상 '중위 후행자는 현재 노드의 오른쪽 서브 트리 가장 좌측 노드'를 기억하시면 편합니다.
이진 검색 트리는 스레드 노드가 없기 때문에 두가지 경우를 생각해주셔야 합니다.
우측 자식 노드가 없는 노드인 경우에
1. 해당 노드가 부모 노드의 좌측 노드이다.
-> 부모 노드가 해당 노드의 중위 후행자 입니다.
2. 해당 노드가 부모 노드의 우측 노드이다.
-> (부모 노드의 부모 노드)가 해당 노드의 중위 후행자 입니다.
=> 이때 (부모 노드)가 (부모 노드의 부모 노드)의 우측 자식 노드 일 경우 해당 노드는 중위 후행자가 없습니다.
위와 같은 경우의 알고리즘이 가장 바깥 if~ else~ 구문의 else~에 구현되어 있습니다.
Node *Find_Suc(Node *root, int data){
Node *cur = Search_Data(root, data); // cur는 중위 후행자를 찾아야할 노드입니다.
Node *tmp;
Node *pr_cur;
tmp = cur ->right_child; // 일단 cur의 우측 서브트리로 갈 준비를 합니다.
if(tmp){ // 오른쪽 서브트리가 있다면,
cur = tmp; // 오른쪽 서브트리의 가장 왼쪽 노드가 tmp일 경우를 대비합니다.
while(cur->left_child){ // 여기서 cur == tmp == cur ->right_child이기 떄문에, cur->left_child == cur ->right_child->left_child입니다.
cur = tmp->left_child; // tmp는 cur ->right_child 입니다.
// 즉, cur은 항상 cur 의 오른쪽 서브트리의 가장 왼쪽으로 이동해 갑니다.
tmp = cur->left_child;
}
}
else{ // 오른쪽 서브트리가 없다면, 위에서 설명 드린 알고리즘이 그대로 구현되어 있습니다.
if(pr->left_child != NULL){
cur = pr;
}
if(pr->right_child != NULL){
pr_cur = pr; // 현재 부모 노드를 저장합니다.
if(pr_cur->right_child->data == cur->data){
Search_Data(root, pr->data); // data 부분에 pr->data가 저장되어 있으므로,
// 해당 함수 이후에 pr은 pr_cur의 부모 노드 == cur의 부모 노드의 부모 노드 입니다.
cur = pr;
if(pr->right_child->data == pr_cur->data){
cur = NULL;
puts("\nNo Successor.");
}
}
}
}
return cur;
}
7) 노드 삭제
조금 어렵습니다.
위에 개념 설명 부분의 그림을 보시면 이해하기 편합니다.
3가지 상황이 있습니다.
지우고자 하는 노드 = cur
1. cur의 자식 노드가 없을 경우
-> cur에 할당된 메모리를 해제합니다.
2. cur의 자식 노드가 1개 있을 경우
-> cur을 삭제하고, 자식 노드가 그 자리를 대체합니다.
3. cur의 자식 노드가 2개 있을 경우
-> cur 자리에 cur의 중위 후행자의 데이터가 저장됩니다.
=> 이후 cur의 중위 후행자를 삭제하는 재귀 함수가 실행됩니다.
void Delete_Data(Node *root, int data){ // 삭제되는 데이터의 자식 노드가 모두 있는 경우에 중위 후행자와 교환된다.
Node *suc;
Node *cur;
Node *tmp;
cur = Search_Data(root, data);
if(cur == NULL){
puts("The data is not in Tree.\n");
}
else{
if(cur->left_child == NULL && cur->right_child == NULL){ // 자식 노드가 없는 경우
if(pr->left_child != NULL){ // 부모 노드의 왼쪽 자식 노드가 있을 때
if(pr->left_child->data == cur->data){ // cur이 왼쪽 자식 노드라면
pr->left_child = NULL; // 부모의 왼쪽 자식에 NULL을 삽입합니다. (cur과 연결 끊음)
}
else{
pr->right_child = NULL; // 왼쪽 자식 노드가 있을 때, cur이 왼쪽 자식 노드가 아니면, 오른쪽 자식이겠죠
}
}
else{ // 부모 노드의 왼쪽 자식 노드가 없을 때
pr->right_child = NULL; // 무조건 cur은 부모 노드의 오른쪽 자식 노드 입니다.
}
free(cur); // cur에 할당된 메모리를 해제합니다.
}
else if(cur->left_child != NULL && cur->right_child != NULL){ // 자식 노드가 2개 있는 경우
suc = Find_Suc(root, data); // 지우고자 하는 노드의 중위 후행자 (successor)
tmp = Init_Tree();
tmp->data = suc->data; // 이 부분 없이 cur->data = suc->data를 해주면,
// 아래 Delete_Data 에서 suc->data와 동일한 노드가 2개 생겨서 오류가 발생합니다.
// 따라서 잠시 tmp에 데이터를 저장해주고,
Delete_Data(root, suc->data) // cur의 중위 후행자를 삭제하고 난 뒤,
cur->data = tmp->data; // cur에 중위 후행자의 데이터를 삽입합니다.
free(tmp); // tmp 대신 int 자료형 변수를 선언해서 사용할 수 있습니다.
// EX) int A = suc->data; => cur->data = A;
// 그냥 위에 선언해놓은 tmp가 아까워서 위와 같이 동적 메모리를 할당해 사용했습니다.
}
else{ // 자식 노드가 1개 있는 경우
tmp = NULL; // 없어도 무관합니다.
if(cur->left_child == NULL){ // right_child에 자식 노드가 있으면
tmp = cur->right_child;
}
if(cur->right_child == NULL){ // left_child에 자식 노드가 있으면
tmp = cur->left_child;
}
cur->data = tmp->data; // cur의 모든 구조체 멤버를 tmp의 구조체 멤버의 정보로 갱신해줍니다.
cur->left_child = tmp->left_child;
cur->right_child = tmp->right_child;
free(tmp); // 이후 tmp는 해제됩니다.
}
}
}
8) 중위 순행 출력
이 부분은 설명을 생략하겠습니다.
void Inorder_Traverse(Node *root){
if(root){
Inorder_Traverse(root->left_child);
printf("%2d ", root->data);
Inorder_Traverse(root->right_child);
}
}
void Print_Tree(Node *root){
puts("\nPrinting starts.");
Inorder_Traverse(root);
printf("\n");
puts("Printing is complete.\n");
}
3-2. 이진 검색 트리 전체 코드 및 출력 결과
1) 전체 코드
#include <stdio.h>
#include <stdlib.h>
/*----------구조체 선언----------*/
typedef struct NODE{
int data;
struct NODE *left_child;
struct NODE *right_child;
} Node;
/*----------------------------*/
Node *pr;
/*----------함수 선언---------*/
Node *Init_Tree(void);
void Input_Data(Node **root, int data);
Node *Search_Data(Node *root, int data);
Node *Find_Suc(Node *root, int data);
void Delete_Data(Node *root, int data);
void Inorder_Traverse(Node *root);
void Print_Tree(Node *root);
/*--------------------------*/
int main(void) {
Node *root = NULL;
Node *tmp;
// Input_Data(&root, 20);
//
// printf("tr->data = %d\n", root->data);
//
// Input_Data(&root, 20);
Input_Data(&root, 20);
Input_Data(&root, 10);
Input_Data(&root, 30);
Input_Data(&root, 5);
Input_Data(&root, 3);
Input_Data(&root, -7);
Input_Data(&root, 6);
Input_Data(&root, -15);
Input_Data(&root, 25);
Input_Data(&root, 25);
Input_Data(&root, 38);
Input_Data(&root, 33);
Input_Data(&root, 37);
#if 0
int n;
while(n != -1){ // 끝내고 싶으면 -1 입력
printf("\nData = ");
scanf("%d", &n);
printf("\n")
tmp = Search_Data(root, n);
if(tmp != NULL)
printf("[%d] = %d\n", n, tmp->data);
}
#endif
#if 1
int n;
Print_Tree(root);
printf("Data = ");
scanf("%d", &n);
Delete_Data(root, n);
Print_Tree(root);
#endif
return 0;
}
Node *Init_Tree(void){
Node *tr = (Node *)malloc(sizeof(Node));
tr->data = 0;
tr->left_child= NULL;
tr->right_child = NULL;
return tr;
}
void Input_Data(Node **root, int data){
Node *rtmp;
Node *tmp = Init_Tree();
Node *cur = *root;
tmp->data = data;
if(*root == NULL){
*root = tmp;
}
else{
if((*root)->data > data){
if((*root)->left_child == NULL){
(*root)->left_child = tmp;
}
else{
rtmp = (*root)->left_child;
Input_Data(&rtmp, data);
}
}
else if(cur->data < data){
if(cur->right_child == NULL){
cur->right_child = tmp;
}
else{
rtmp = cur->right_child;
Input_Data(&rtmp, data);
}
}
else{
puts("The input data is already in Tree.\n");
}
}
}
Node *Search_Data(Node *root, int data){
Node *cur;
Node *tmp = NULL;
cur = root;
pr = NULL;
while(cur != NULL){
if(cur->data > data){
pr = cur;
cur = cur->left_child;
}
else if(cur->data < data){
pr = cur;
cur = cur->right_child;
}
else{
tmp = cur;
break;
}
}
return tmp;
}
Node *Find_Suc(Node *root, int data){
Node *cur = Search_Data(root, data);
Node *tmp;
Node *pr_cur;
tmp = cur->right_child;
if(tmp){
cur = tmp;
while(cur->left_child){
cur = tmp->left_child;
tmp = cur->left_child;
}
}
else{
if(pr->left_child != NULL){
cur = pr;
}
if(pr->right_child != NULL){
pr_cur = pr;
if(pr_cur->right_child->data == cur->data){
Search_Data(root, pr->data);
cur = pr;
if(pr->right_child->data == pr_cur->data){
cur = NULL;
puts("\nNo Successor.");
}
}
}
}
return cur;
}
void Delete_Data(Node *root, int data){ // 삭제되는 데이터의 자식 노드가 모두 있는 경우에 중위 후행자와 교환된다.
Node *suc;
Node *cur;
Node *tmp;
cur = Search_Data(root, data);
if(cur == NULL){
puts("The data is not in Tree.\n");
}
else{
if(cur->left_child == NULL && cur->right_child == NULL){
if(pr->left_child != NULL){
if(pr->left_child->data == cur->data){
pr->left_child = NULL;
}
else{
pr->right_child = NULL;
}
}
else{
pr->right_child = NULL;
}
free(cur);
}
else if(cur->left_child != NULL && cur->right_child != NULL){
suc = Find_Suc(root, data); // 지우고자 하는 노드의 중위 후행자 (successor)
tmp = Init_Tree();
tmp->data = suc->data;
puts("1");
Delete_Data(root, suc->data); // 내가 지우고 싶은게 중복된다.
cur->data = tmp->data;
free(tmp);
}
else{
tmp = NULL;
if(cur->left_child == NULL){ // right_child에 자식 노드가 있으면
tmp = cur->right_child;
}
if(cur->right_child == NULL){ // left_child에 자식 노드가 있으면
tmp = cur->left_child;
}
cur->data = tmp->data;
cur->left_child = tmp->left_child;
cur->right_child = tmp->right_child;
free(tmp);
}
}
}
void Inorder_Traverse(Node *root){
if(root){
Inorder_Traverse(root->left_child);
printf("%2d ", root->data);
Inorder_Traverse(root->right_child);
}
}
void Print_Tree(Node *root){
puts("\nPrinting starts.");
Inorder_Traverse(root);
printf("\n");
puts("Printing is complete.\n");
}
2) 출력 결과
데이터를 무작위로 입력하였을 때 다음과 같이 중회 순회를 이용한 출력 결과는 크기 순서대로 정렬됩니다.

저장된 데이터를 반환하는 함수를 사용해 출력한 결과는 다음과 같습니다.

저장된 데이터를 삭제하는 함수를 사용해 출력한 결과는 다음과 같습니다.
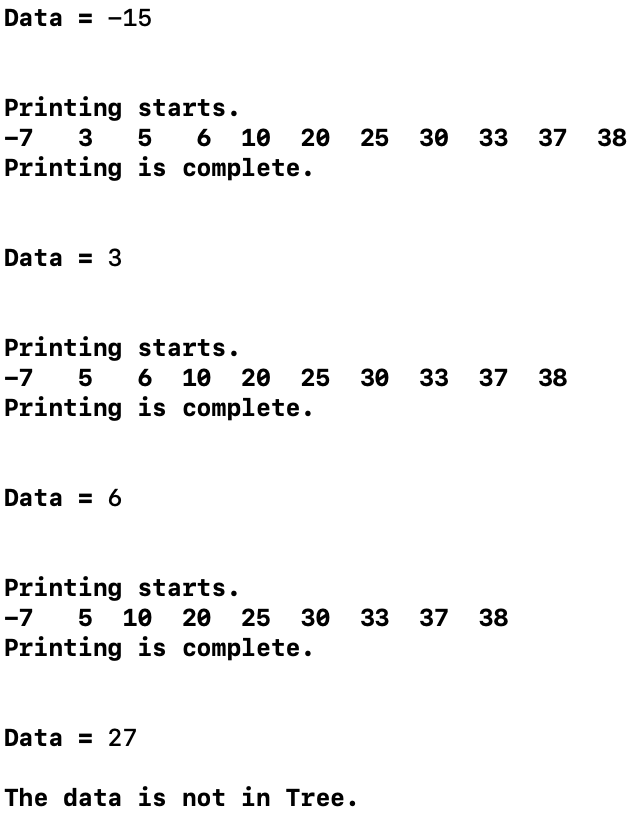
삭제를 하는 윈리의 큰 목적은 중위 순회 시 순서 변경을 최소로 줄이는 것입니다.
따라서 특정 노드를 삭제 한 후에 중위 순회를 이용해 트리를 출력하면,
이전 출력 결과에서 지운 노드의 데이터만 사라진 것을 확인 할 수 있습니다.
'Programming > C' 카테고리의 다른 글
| [자료구조 C 언어] C 프로그래밍 자료구조 - 16 : 그래프(2) 기초 연산: 깊이 우선 탐색, 넓이 우선 탐색 등 (0) | 2020.03.19 |
|---|---|
| [자료구조 C 언어] C 프로그래밍 자료구조 - 15 : 그래프(1) 기본 개념 (0) | 2020.03.18 |
| [자료구조 C 언어] C 프로그래밍 자료구조 - 13 : 힙 트리 (Heap Tree)와 우선 순위 큐 (Priority Queue) (0) | 2020.03.16 |
| [자료구조 C 언어] C 프로그래밍 자료구조 - 12 : 스레드 이진 트리 (Thread Binary Tree) (0) | 2020.03.16 |
| [자료구조 C 언어] C 프로그래밍 자료구조 - 11 : 트리, 이진 트리의 개념 (Tree, Binary Tree) (0) | 2020.03.11 |