- 시그모이드 함수
: 로지스틱 회귀분석 또는 neural network의 binary classification 마지막 레이어의 활성함수로 사용한다.
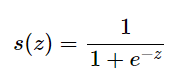
1) 로지스틱 회귀분석 : 데이터를 두 개의 그룹으로 분류하는 가장 기본적인 방법이다.
1] 회귀분석과의 차이는 우리가 원하는 것이 실수인 예측값이기 때문에 종속변수의 범위가 실수이지만 로지스틱 회귀분석에서는 종속변수 y의 값이 0 또는 1을 갖는다.
2] 따라서 로지스틱 회귀분석을 사용할 때는 주어진 데이터를 분류할 때 0인지 1인지 예측하는 모델을 만들어야 한다.
2) 로지스틱 회귀분석 시 시그모이드 함수를 사용하는 이유
1] 데이터를 두 개의 그룹으로 분류할 때 선형함수 (직선)을 사용한다면, 다음과 같은 문제가 발생한다.
-> 특정한 data set을 성공 (y = 1)과 실패 (y = 0)으로 분류한다고 하자.
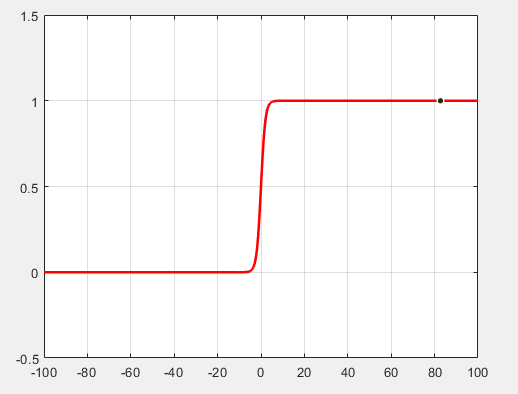
-> 이 때 data set은 다음과 같다 : (1, 0), (2, 0), (3, 0), (8, 1), (9, 1), (10, 1)
-> 해당 data set은 y = 1/2를 기준으로 성공과 실패를 나누면 된다고 할 수 있다.
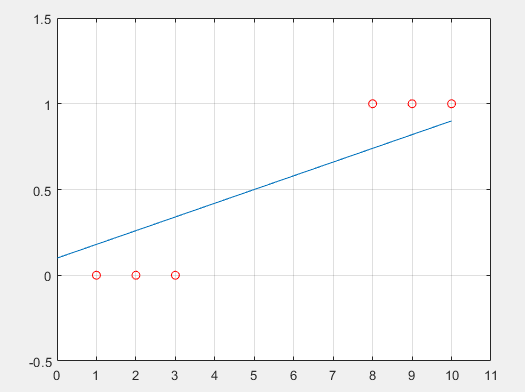
-> 이 때 (20, 1)의 값을 가지는 data가 추가 되었다고 하자.
-> 데이터를 분류하는 선형 함수 (직선)은 다음과 같은 모양이 될 것 이다.
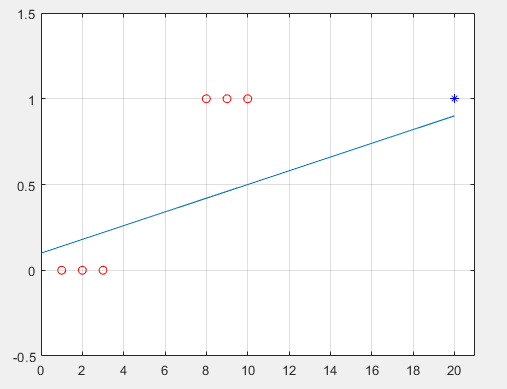
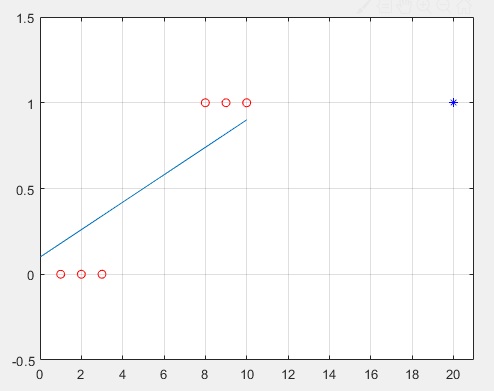
-> 이때 데이터를 분류하는 함수로 시그모이드를 활용하면,
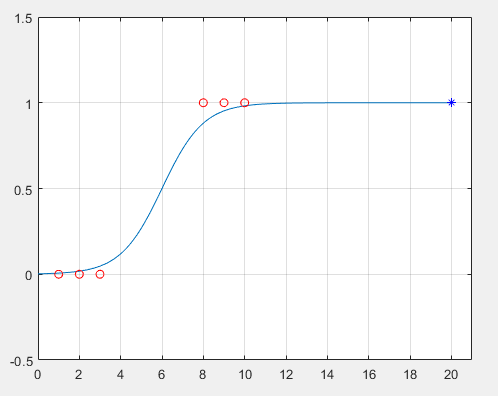
-> 더욱 명확하게 분류할 수 있다!!
2] 시그모이드를 사용하는 더욱 명확한 이유
-> 단순선형회귀분석 (독립변수가 1개인 경우)은 목표가 실수값 예측이기 떄문에 선형함수 y = w*x +b를 사용한다.
-> 로지스틱 회귀분석에는 종속변수가 0 또는 1이기 때문에 선형함수를 사용하는 것은 의미가 없고, Odds를 이용한다.
-> Odds는 다음과 같이 정의된다. (확률 P가 주어져 있을 때)
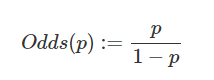
-> 확률 p의 범위가 (0, 1)이라면 Odds(p)의 범위는 (0, ∞)이 된다.
-> Odds에 로그함수를 취한 log(Odds(p))는 범위가 (-∞, ∞)이 된다.
=> 실수 전체를 의미한다. ==> 즉, 범위가 실수 전체이므로 이 값에 대해선 선형회귀분석을 하는 것이 의미가 있다.

-> 위의 식으로 선형회귀분석을 실시해서 w와 b를 얻을 수 있다.
-> 해당 식을 p로 정리하면 다음과 같은 식을 얻는다.
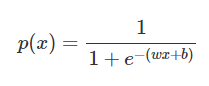
-> 결과적으로 x 데이터가 주어졌을 때 성공확률을 예측하는 로지스틱 회귀분석은 학습데이터를 잘 설명하는 시그모이드 함수의 w와 b를 찾는 문제이다.
'Study > Reinforcement learning' 카테고리의 다른 글
| 강화학습_(4) - Math Preliminary_2 (0) | 2019.10.23 |
|---|---|
| 강화학습_(4) - Math Preliminary_1 (0) | 2019.10.22 |
| 강화학습_(2) - Python 기초_4 (0) | 2019.10.20 |
| 강화학습_(2) - Python 기초_3 (0) | 2019.10.20 |
| 강화학습_(2) - Python 기초_2 (0) | 2019.10.20 |