References : 조행래 교수님 (영남대학교), 박종혁 교수님 (서울과학기술대학교)의 강의 / 강의자료에 기반한 내용입니다. + 제가 공부한 내용
이번 게시물에선 희소 행렬과 행렬 전치에 대해서 간단히 다뤄보도록 하겠습니다.
원래 저번 게시물에 같이 포함됐어야 하는데 너무 분량이 많아져서 따로 뺐습니다.
1. 희소 행렬 (Sparse matrix)

간단하게 0이 많이 포함된 행렬을 말합니다.
1-1 희소 행렬의 표현
0이 많이 포함된 행령이니까 최대한 공간 낭비를 줄이는 것이 핵심입니다.
우선 0이 아닌 항들의 행과 열, 값을 저장하는 방법이 있습니다.
<row, column, value>
전치행렬을 쉽게 만들기 위해 저장 시 row를 오름차순으로 정렬합니다.

2. 행렬의 전치 (Transpose of a matrix)
행렬의 행과 열의 위치를 바꾸는 것을 전치라고 합니다.

연산은 굉장히 쉽습니다.
행렬 A[i][j] = a_ij (i (행) = 0, 1, ..., M // j (열) = 0, 1, ..., N)
행렬 A의 데이터는 그대로 두고, 행과 열의 인덱스만 교환해줍니다.
행렬 B[j][i] = b_ji = a_ij (j (행) = 0, 1, ..., N // i (열) = 0, 1, ..., M)
2-1 행렬의 전치 구현
#include <stdio.h>
typedef struct { //행렬 원소를 저장하기 위한 구조체 term 정의
int row;
int col;
int value;
} term;
void smTranspose(term a[], term b[]) {
int i, j, currentb;
b[0].col = a[0].row; // 전치행렬 b의 행 수 = 희소행렬 a의 행 수
b[0].row = a[0].col; // 전치행렬 b의 열 수= 희소행렬 a의 열 수
b[0].value = a[0].value; // 전치행렬 b의 원소 수 = 희소행렬 a에서 0이 아닌 원소수
if (a[0].value > 0) { //0이 아닌 원소가 있는 경우에만 전치 연산 수행
currentb = 1;
for (i = 0; i < a[0].col; i++) //희소행렬 a의 열별로 전치 반복 수행
for (j = 1; j <= a[0].value; j++) //0이 아닌 원소 수에 대해서만 반복 수행
if (a[j].col == i) { //현재의 열에 속하는 원소가 있으면 b[]에 삽입
b[currentb].row = a[j].col;
b[currentb].col = a[j].row;
b[currentb].value = a[j].value;
currentb++;
}
}
}
int main(void){
int i, j;
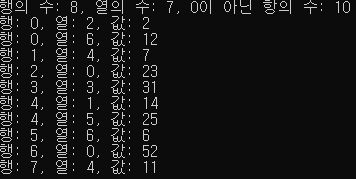
term A[11] = { {8,7,10}, {0,2,2}, {0,6,12}, {1,4,7}, {2,0,23}, {3,3,31}, {4,1,14}, {4,5,25}, {5,6,6}, {6,0,52}, {7,4,11} };
term B[11];
smTranspose(A, B);
printf("행의 수: %d, 열의 수: %d, 0이 아닌 항의 수: %d\n", A[0].row, A[0].col, A[0].value);
for (i = 1; i < 11; i++)
printf("행: %d, 열: %d, 값: %d\n", A[i].row, A[i].col, A[i].value);
printf("\n\n");
smTranspose(A, B);
printf("Transpose processing has been finished.\n");
printf("\n\n");
printf("행의 수: %d, 열의 수: %d, 0이 아닌 항의 수: %d\n", B[0].row, B[0].col, B[0].value);
for (i = 1; i < 11; i++)
printf("행: %d, 열: %d, 값: %d\n", B[i].row, B[i].col, B[i].value);
printf("\n\n");
return 0;
}
출력 결과입니다.
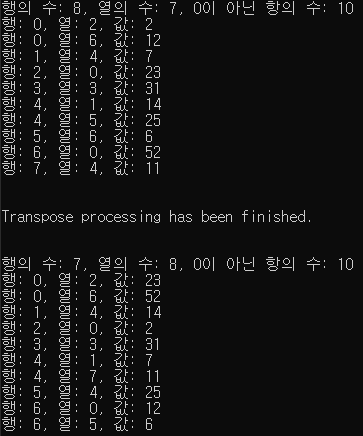
아주 잘 되었습니다.
하지만 약간의 문제가 있습니다.
해당 알고리즘의 시간 복잡도는 O(columns*elements)입니다.
O(columns*elements) = O(columns*(colulmns*rows)) = O(coulumns^2*rows) 로 치환 될 수 있습니다.
즉, 0이 아닌 항이 많아질수록 기하 급수적으로 늘어나게 됩니다.
따라서 다음과 같은 fast transpose를 사용할 수도 있습니다.
2-2 Fast Transpose
기본 개념은 각 column이 저장될 곳을 미리 파악하는 것입니다.
따라서 column index 저장을 위한 추가적인 공간이 필요합니다.
메모리에선 이전보다 손해를 보지만 시간 복잡도는 내려가는 효과를 보는 방법입니다.

사진을 보고 잘 이해가 안 가실 것 같아서 바로 코드를 통해 설명드리겠습니다.
개념을 꼭 숙지하고 알고리즘을 확인해주세요.
큰 골자는 행렬 A에서 0이 아닌 항을 가진 열들이 각각 몇 번 나오는 지 저장하는 행렬을 만들어줍니다.
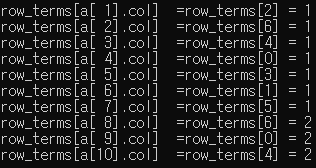
위에서 행렬 A의 0번째 열은 2번, 1번째 열은 1번, 2번째 열은 2번 나옵니다.
그리고, 행렬 A의 0번째 열을 제외한 1, 2, 3, ..., N번째 열에게 자기 앞 열들이 몇번 나오는지 알려줍니다.
위에서 1번째 열 앞에 0번째 열이 2번 나오므로, 1번째 열에게 2를 알려줍니다.
위에서 2번째 열 앞에 0번째 열이 2번, 1번째 열이 1번 나오므로, 2번째 열에게 3를 알려줍니다.
그 다음 알려준 숫자+1 번째를 j라고 할 때 행렬 B의 j 번째 행에 해당 열의 항을 전치해서 저장합니다.
위에서 행렬 A의 2번째 열에게 알려준 숫자는 3이므로, 행렬 B의 4번째 행에 행렬 A의 2번째 열의 항을 전치해서 넣어줍니다.
void fast_transpose(term a[], term b[]) {
int row_terms[MAX_COL];
int starting_pos[MAX_COL];
int i, j;
int num_col = a[0].col;
int num_terms = a[0].value;
b[0].row = num_col;
b[0].col = a[0].row;
b[0].value = num_terms;
if (num_terms > 0) {
for (i = 0; i < num_col; i++) {
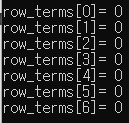
row_terms[i] = 0; // A 행렬의 열 갯수 만큼 row_terms의 배열을 0으로 초기화 해줍니다.
printf("row_terms[%d]= %d\n", i, row_terms[i]);
}
printf("\n\n");
for (i = 1; i <= num_terms; i++) {
row_terms[a[i].col]++; // A 행렬의 열 인덱스에 해당하는 row_terms의 배열을 1로 초기화 해줍니다.
printf("row_terms[a[%2d].col] =row_terms[%d] = %d\n", i, a[i].col, row_terms[a[i].col]);
}
printf("\n\n");
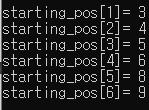
starting_pos[0] = 1;
for (i = 1; i < num_col; i++) {
starting_pos[i] = starting_pos[i - 1] + row_terms[i - 1];
printf("starting_pos[%d]= %d\n", i, starting_pos[i]);
}
printf("\n\n");
// starting_pos의 인덱스에는 행렬 A의 열 번호가 들어갑니다.
// starting_pos[1] = stating_pos[0] + row_terms[0]
// starting_pos[1] = 1 + A 행렬에서 0번째 열에서 0이 아닌 항의 수 만큼
// starting_pos[1] = 1 + 2 =3
// 즉, A 행렬에서 1번째 열 (starting_pos의 인덱스가 1일 때) 앞에는
// A 행렬의 0번째 열의 항들이 B 행렬에 전치해서 2번 들어가니까
// A 행렬의 1번째 열의 항들은 B 행렬의 3번 부터 전치해서 저장해라
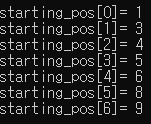
for (i = 0; i < num_col; i++) {
printf("starting_pos[%d]= %d\n", i, starting_pos[i]);
}
printf("\n\n");
// 예를들어 A에서 0번째 열의 항이 2개가 있고, 1번째 열의 항이 1개, 2번째 열의 항이 1개가 있습니다.
// 1번째 열의 항에겐 "너 앞에 0번째 열의 항 2개가 먼저 자리 잡아야 한다."고 알려줍니다.
// -> 행렬 A의 1번째 열의 행렬 B에서 행의 값의 시작은 3번째 입니다. (j = 3입니다.)
// => 그래서 starting_pos[1] = 3입니다.
// 2번째 열의 항에겐 너 앞에 0번째 열의 항 2개와 1번째 열의 항 1개, 즉, 3개의 항이 먼저 자리 잡아야 한다고 알려줍니다.
// -> 행렬 A의 2번째 열의 행렬 B에서 행의 값의 시작은 4번째 입니다. (j = 4입니다.)
// => 그래서 starting_pos[2] = 4입니다.
// 당연히 행렬 A의 0번째 열의 행렬 B에서 행의 값의 시작은 1번째 입니다. (j = 1입니다.)
// -> j = 0에는 행, 열, 값의 정보가 들어갑니다.
// => 그래서 starting_pos[0] = 1입니다.
// => 행렬 A의 0번째 열의 항 갯수는 2개이므로, 밑에 for문에서 starting_pos[0](= 1)을 j에 넣어준 뒤 ++ 연산을 통해 1 증가킵니다.
// => 이후 다시 starting_pos[0](= 2)이 선언될 때 j에 2가 삽입됩니다.
for (i = 1; i <= num_terms; i++) {
j = starting_pos[a[i].col]++;
printf("j = %2d = starting_pos[a[%2d].col]++ = starting_pos[%d]++\n", j, i, a[i].col);
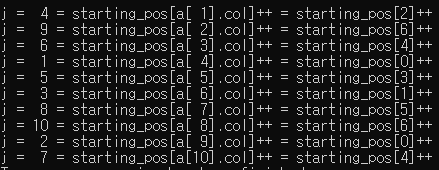
b[j].row = a[i].col;
b[j].col = a[i].row;
b[j].value = a[i].value;
}
}
}
main 함수에는 이전에 trasnpose를 fast_transpose로만 바꿔주면 됩니다.

해당 알고리즘의 시간 복잡도는 O(colums + elements)로 앞선 방법 보다 항의 증가에 대해서 시간 복잡도의 증가 폭이 훨씬 적습니다.
'Programming > C' 카테고리의 다른 글
| [자료구조 C 언어] C 프로그래밍 자료구조 - 5 : 배열을 사용한 큐 (Queue) (0) | 2020.03.04 |
|---|---|
| [자료구조 C 언어] C 프로그래밍 자료구조 - 4 : 배열을 사용한 스택 (Stack) (0) | 2020.03.04 |
| [자료구조 C 언어] C 프로그래밍 자료구조 - 3 : 순서 리스트, 다항식의 표현 (0) | 2020.02.27 |
| [자료구조 C 언어] C 프로그래밍 자료구조 - 2 : 배열과 구조체 (0) | 2020.02.27 |
| [자료구조 C 언어] C 프로그래밍 자료구조 - 1 : 자료구조와 알고리즘의 개념, 알고리즘 복잡도 (시간 복잡도) (0) | 2020.02.26 |