References : 조행래 교수님 (영남대학교), 박종혁 교수님 (서울과학기술대학교)의 강의 / 강의자료에 기반한 내용입니다.
+ 제가 공부한 내용
이제 기초 공부는 어느정도 했으니까
본격적으로 자료구조와 알고리즘에 대해 알아보겠습니다.
자료구조 : Array, Stack, Queue, List, Tree, Graph
자료구조를 이용한 알고리즘 : Sorting, Searching
위에 개념들이 자료구조에 대한 기본 사항이라고 합니다.
사실 제어기를 만들 때 (PID, MPC, LQR 등) 위의 개념은 잘 사용하지 않습니다.
보통 기업에서 코딩 테스트를 볼 때 위의 개념들에 관한 문제를 많이 낸다고 알고 있습니다.
추가로 dynamic programming 정도가 있겠죠.
(다른 게시물에 간단한 개념이 정리되어 있습니다.)
자료구조에 대한 게시물이 마무리 되면, 그 다음에는 백준과 같은 코딩 관련 사이트의 문제를 함께 풀어보는 게시물을 업로드 할 예정입니다.
1. 자료구조
- 문제 해결을 위해 데이터를 조직하여 표현하는 방법
- 주어진 문제의 특성에 맞는 자료구조를 선택하면 프로그램 개발이 쉬워지고, 성능이 향상된다.
EX)
전화번호부 : 배열, 연결 리스트, 트리
수강신청, 연말정산 대기 줄 : 큐
지하철 노선도 : 그래프 (역 이름, 역 간의 선후 관계)
1) 추상 데이터 타입 (Abstract Data Type, ADT)
- 자료구조를 기술할 때 사용하는 방법
- 데이터 객체 및 연산의 명세와 데이터 객체의 내부 표현양식/연사느이 구현 내용 분리
=> 다시 말하면, 속에 복잡한 사정은 안 보여주고 딱 쓸 만큼만 보여준다는 것입니다.

2. 알고리즘
- 문제 해결을 위해 특정한 일을 수행하는 명령어들의 집합
- 입력, 출력, 명확성, 유한성, 유효성/실행가능성 등의 조건을 만족해야한다.
1) 알고리즘의 표현
1] 자연어
- 구어체와 비슷하게 표현, 코드에 대해 잘 몰라도 이해하기는 쉽다
EX) 이진 검색
- left = 0, right = n-1. middle = (left+right)/2로 두자.
- list[middle]과 key를 비교하여, 아래 경우들을 처리
=> list[middle] < key: key가 list[middle+1]부터 list[right]에 있으므로, 다시 조사
=> list[middle] = key: middle을 반환
=> list[middle] > key: key가 list[left]부터 list[middle-1]에 있으므로, 다시 조사
2] 유사코드 (pseudo code)
- 완벽하게 코드로 사용할 수는 없지만, 논리 순서대로 코드 진행 사항을 표현한다.

3] 프로그래밍 언어
- 완벽하게 코드로 사용할 수 있는 방법.

3. 순환 알고리즘 (Recursive Algorithm)
- 자기 자신을 다시 호출하는 알고리즘입니다.
- 함수 진행 중에 다시 실행중인 함수를 호출합니다.
(내 안에 내가 너무도 많아~)
=> 항상 종료를 위한 경계 조건이 설정되야 합니다.
=> 각 단계 마다 경계 조건에 접근하도록 알고리즘을 재귀 호출해야 합니다.
EX) 팩토리얼 계산
int factorial(int n) {
if (n <= 1) // 경계 조건
return 1;
else
return n * factorial(n-1);
}
EX) 이진 검색
int binsearch(int list[], int key, int left, int right)
{
int middle;
if (left <= right) { // 경계 조건 middle = (left + right) / 2;
switch (compare(list[middle], key)) {
case -1: // 경계 조건에 접근
return binsearch(list, key, middle+1, right);
case 0:
return middle;
case 1: // 경계 조건에 접근
return binsearch(list, key, left, middle-1);
}
}
return -1;
}
4. 알고리즘의 복잡도 계산
본인이 작성한 알고리즘의 성능을 분석할 때 사용할 수 있습니다.
같은 목적을 가진 알고리즘이라도 알고리즘의 복잡도 더 적은 알고리즘이 더 좋습니다.
크게 공간 복잡도와 시간 복잡도가 있는데, 최근엔 메모리의 용량이나 가격이 많이 내려가서 시간 복잡도가 우선 된다고 합니다.
1) 프로그램의 평가 기준
- 주어진 문제를 해결, 정확성 => 필수
- 문서화, 모듈화, 가독성 => 좋은 프로그래밍 습관
- 공간 효율, 시간 효율 => 성능과 관련
프로그램 개발 중 주석을 잘 작성 해놓거나 마지막 업데이트 시간 및 내용을 기록하는 것이 참 중요합니다.
코딩을 막 하는 중에는 머리가 핑핑 잘 돌아가는데 시간이 흐른 뒤 다시 코드를 뜯어보면, 아.. 그때의 나는 참 똑똑했구나 하고 다시 이해하기에 시간이 꽤 걸립니다.
가독성은 배열 이름을 arr로 한다거나, 그 배열을 가리키는 포인터를 parr 등으로 이름을 설정하는 것입니다.
함수를 생성할 땐 더하기 함수는 add, 빼기는 sub나 minus 등으로 정하면 나중에 누구든 이름으로 유추할 수 있겠죠.
모듈화는 본인 뿐만 아니라 다수가 함께 작업할 때 참 유용합니다.
모듈을 하나하나 잘 만들어 놓으면 공유하기도 좋고, 수정도 용이합니다.
2) 시간 복잡도 (Time Complexity)
1] 실행에 걸리는 시간 = 컴파일 시간 + 실행 시간
- 컴파일러 option과 하드웨어 사양에 따라 가변한다.
- 프로그램 단계 수를 활용한다.
2] 프로그램 단계 수 (Program Step)
- 프로그램의 문법적인 혹은 논리적인 단위
- 프로그램 단계 수의 계산 (두가지)
1. 프로그램에 count를 증가시키는 문장을 추가한다.
2. 테이블 방식을 사용한다.
3) 테이블 방식
바로 예시를 통해 설명 드리겠습니다.
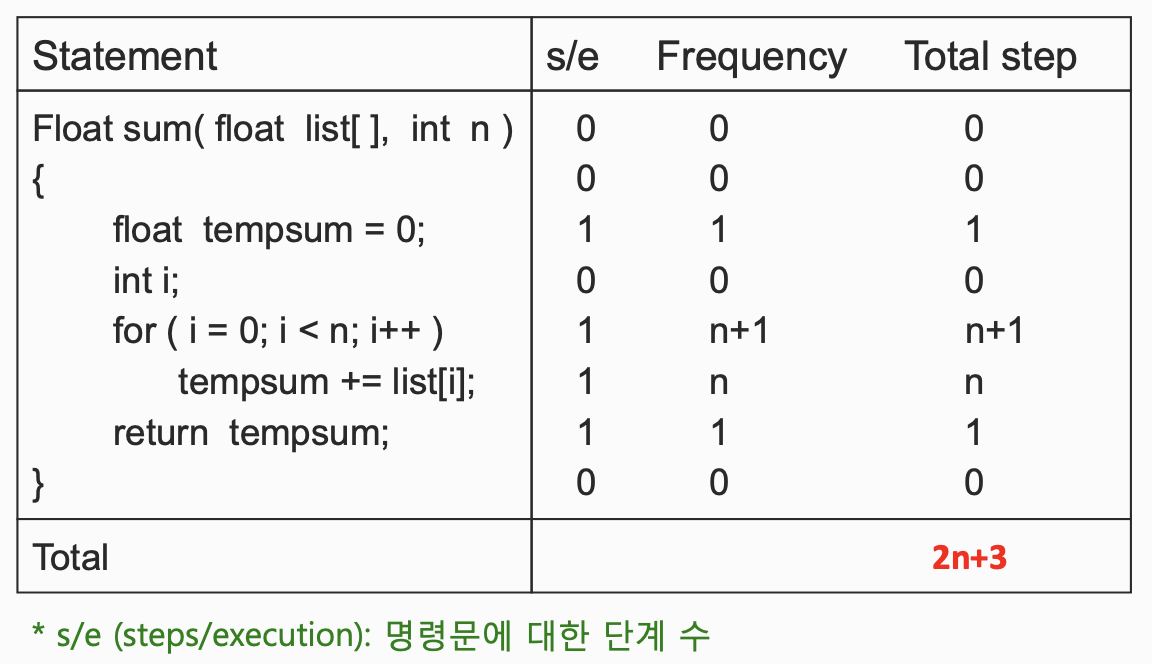
무언가를 선언하는 것은 단계 수에 들어가지 않습니다.
입력하거나 출력하는 건 단계수에서 1개로 계산합니다.
for문에서 i가 0에서 n-1까지 증가하다가 n이 됐을 때 for 문이 더이상 실행되지 않고 종료합니다. => 0~n => n+1 step
for문 내에서 tempsum은 i가 0에서 n-1까지 증가할 때 실행됩니다. => 0~n-1 => n step
return은 출력이니까 1 step으로 계산됩니다.
따라서 sum이라는 함수의 총 단계 수는 2n+3입니다.
예시 하나만 더 보고 넘어가겠습니다.
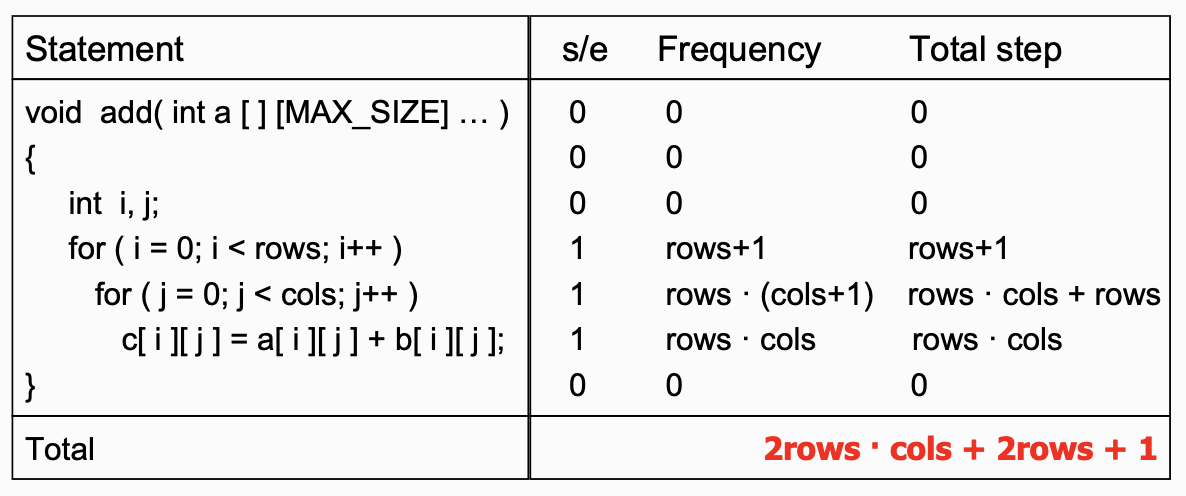
위와 동일하게 첫번째 for 문에서는 rows+1 만큼 step이 쌓입니다.
그 다음 for 문에서는 해당 for 문이 단독으로 있다면 cols+1 만큼 step이 쌓이겠지만, 이전 for문에 의해 rows 만큼 반복되기 때문에 rows*( cols + 1) [step]이 쌓입니다.
두번째 for 문 내의 내용은 단독으로 있을 땐 당연히 cols 만큼 반복됩니다. 하지만 첫번째 for 문에 의해 이전과 마찬가지로 rows*cols [step]이 쌓이게 됩니다.
결과적으로 add 함수를 실행 할 때 2*rows*cols + 2*rows + 1 [step]을 거쳐 실행됩니다.
4) 점근 표기법
항상 저렇게 정확한 프로그램 단계 수를 계산하는 것이 쉽지 않기 때문에 사용하는 방법입니다.
예를 들어 100n+10과 30n+30을 비교해보겠습니다.
n = 2/7 일 때를 기점으로 100n+10의 크기가 더 커지게 됩니다.
그럼 누가 더 빠른 걸까요..?
점근 표기법은 위에서 확인한 프로그램 단계 수를 각각의 기준에 맞춰 근사해줍니다.
큰 맥락만 보자는 거죠...
어차피 일차 함수끼리는 나중에 크기가 역전되는 순간이 있을 거 그냥 i*n으로 퉁치자 이런 식입니다.
자세히 알아보겠습니다.
1] BIg-Oh (O)
- 정의 : f(n) = O(g(n))
모든 n에 대해서 f(n) <= c*g(n) 일 때 O(g(n))으로 f(n)의 시간 복잡도를 표기합니다.
이때 c와 n0는 항상 0보다 커야하고, n은 n0보다 크거나 같아야합니다.
EX)
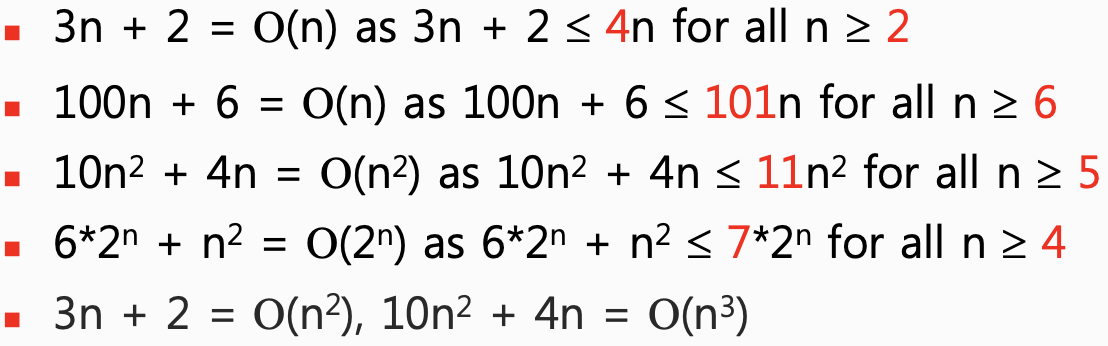
제가 느낀 건 마지막 줄 처럼 아예 높은 수로 c를 정해버리면 다 장땡 아닌가 싶었습니다.
그래서 다음과 같이 다른 기준을 가진 점근 표기법이 있습니다.
2] Omega (Ω)
- 정의 : f(n) = Ω(g(n))
모든 n에 대해서 f(n) >= c*g(n) 일 때 Ω(g(n))으로 f(n)의 시간 복잡도를 표기합니다.
이때 c와 n0는 항상 0보다 커야하고, n은 n0보다 크거나 같아야합니다.
부등호 방향이 바꼈습니다.
즉, g(n)은 f(n)의 lower bound 입니다.
EX)
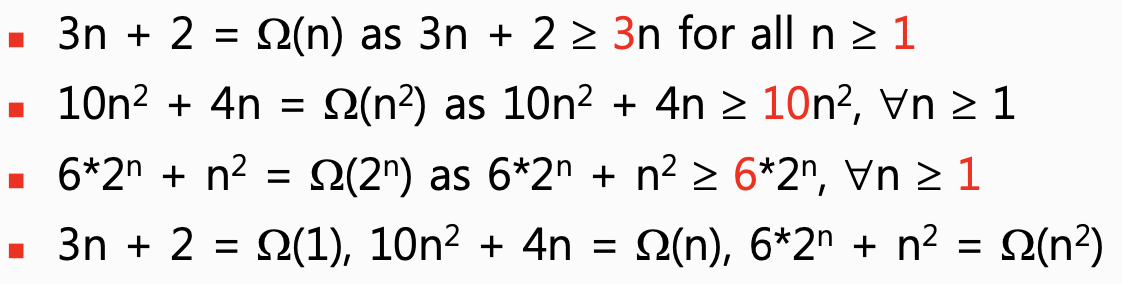
이것도 마찬가지로 엄청 작은 숫자로 해버리면 장땡입니다.
이럴거면 뭐하러 시간 복잡도를 정하는걸까요...
그래서 다음은 위에 두가지 방법을 혼용한 방식입니다.
3] Theta (Θ)
- 정의 : f(n) = Θ(g(n))
모든 n에 대하여 c1*g(n) <= f(n) <= c2*g(n) 일 때 Θ(g(n))으로 f(n)의 시간 복잡도를 표기합니다.
이때 c1, c2, n0는 항상 0보다 커야하고, n은 n0보다 크거나 같아야합니다.
Theta 방법에서 g(n)은 f(n)의 lower bound이자 upper bound 입니다.
EX)

테이블 방식에서 예제였던 알고리즘들을 점근 표기법으로 바꿔 보시면 정리하시는데 도움이 될 겁니다.
정답은 다음과 같습니다.
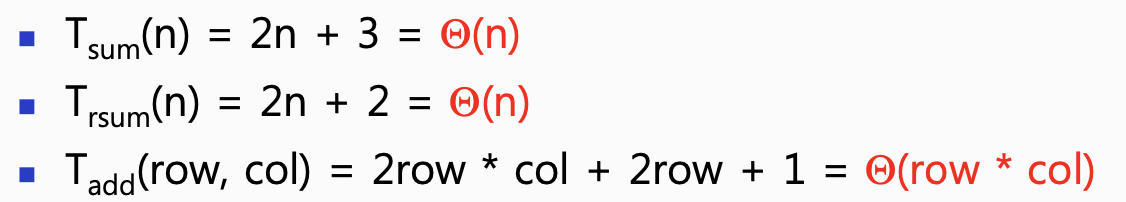
'Programming > C' 카테고리의 다른 글
| [자료구조 C 언어] C 프로그래밍 자료구조 - 3 : 순서 리스트, 다항식의 표현 (0) | 2020.02.27 |
|---|---|
| [자료구조 C 언어] C 프로그래밍 자료구조 - 2 : 배열과 구조체 (0) | 2020.02.27 |
| [자료구조 C 언어] C 프로그래밍 기초 - 7 : 이중 포인터와 2차원 배열의 관계 (4) | 2020.02.25 |
| [자료구조 C 언어] C 프로그래밍 기초 - 6 : 2차원 배열, 포인터 배열, 배열 포인터 (2) | 2020.02.24 |
| [자료구조 C 언어] C 프로그래밍 기초 - 5 : 포인터 뿌시기 (Pointer) (1) | 2020.02.23 |