이번에는 연결리스트에 대해서 알아보겠습니다.
연결리스트 중에도 단일 연결리스트에 대해 먼저 알아보겠습니다.
(단일 연결리스트는 노드가 단방향으로 연결되는 것이고, 이중 연결리스트는 양방향으로 연결되는 것입니다.)
한마디로 말하자면, 메모리나 주소에 대한 이점은 없지만 수정이 상당히 용이합니다.
중간을 끊고 데이터를 삽입하고, 전체 순서를 뒤집고, 이것저것 하기가 편합니다.
1. 연결리스트
연결리스트가 무엇인지 그림으로 먼저 보겠습니다.

위 그림 (그림 1)과 같이 하나의 노드는 데이터를 저장하는 부분과 다음 노드를 가리키는 구조체 포인터 부분으로 나뉘어 있습니다.
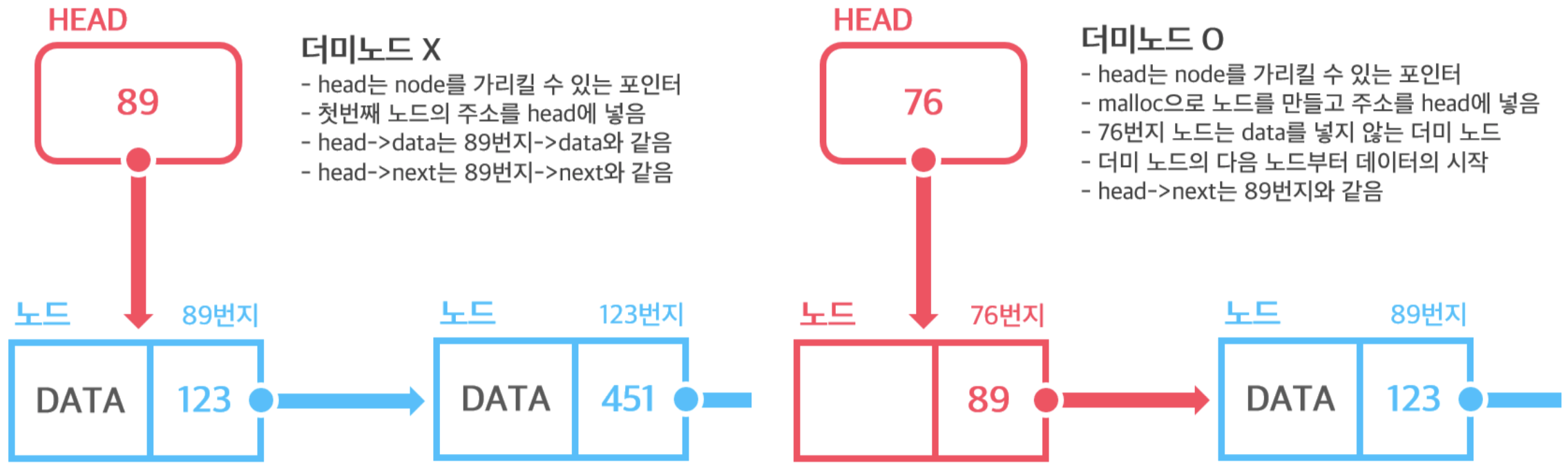
Head를 표현하는 방법 (그림 2)은 데이터를 가지는 방식과 그렇지 않은 방식 (연결리스트의 맨 앞과 맨 뒤의 주소만 포함하는 방식 : 더미 노드 O)이 있습니다.
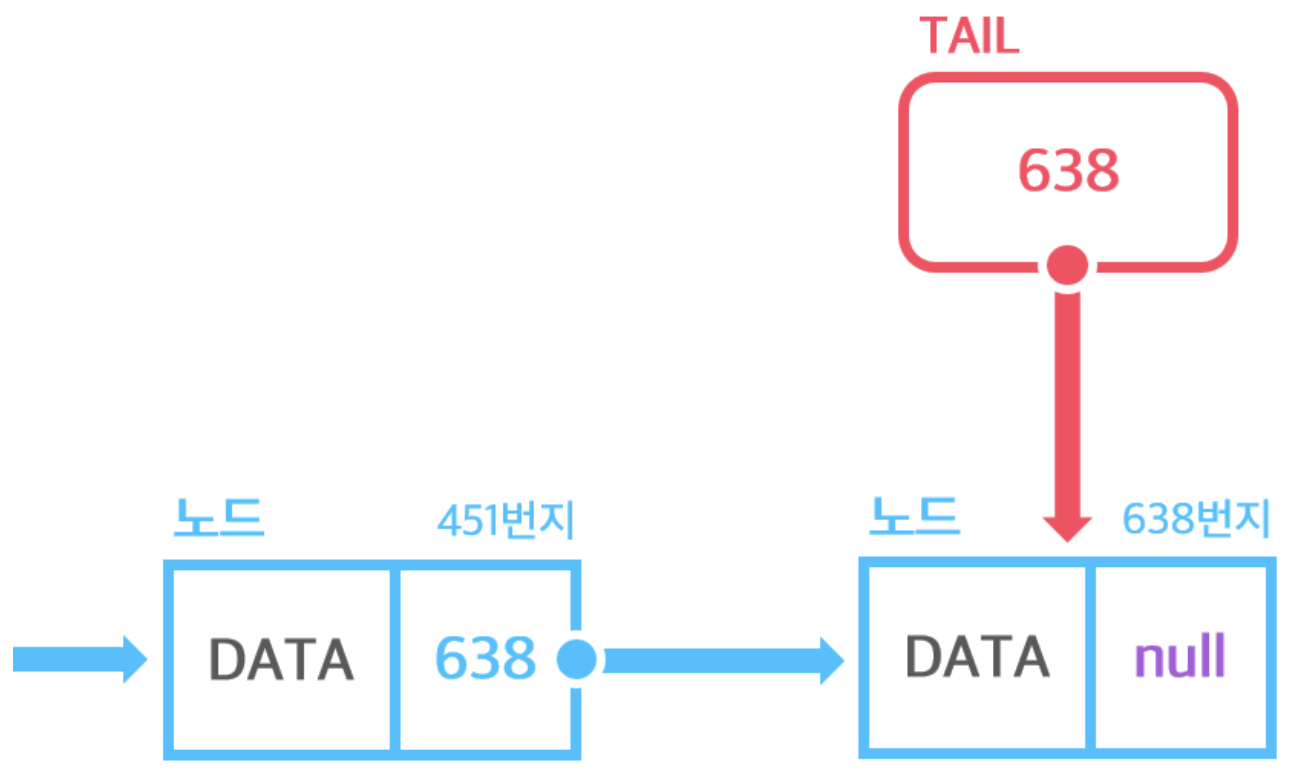
Tail은 아래 그림 (그림 3)과 같이 마지막 노드의 주소만을 포함하고 있습니다.
해당 게시물에선 후자를 선택하여 프로그램을 구성해보겠습니다.
전자에 비해 조건문을 구성하는 부분이 줄어들어 프로그램이 간결하고 직관적이게 됩니다.
1) 연결리스트 Basic
바로 연결리스트와 관련된 기능들을 구현하기 힘드니까 어떤 개념들이 필요한지 한번 공부하고 가겠습니다.
언제나 그렇듯 기초 (구조체 포인터, 자기 참조 구조체, 단일 연결리스트)가 필요 없는 분들은 2) 연결리스트 ADT로 넘어가주세요.
1-1) 구조체 포인터
제일 먼저 중요하게 집고 가야할 것은 구조체도 하나의 자료형으로 보는 것입니다.
즉, 아래와 같이 선언된 구조체가 있을 때를 가정하겠습니다.
typedef struct A{
int a;
int b;
} AA;
이때 struct A 자체를 하나의 자료형이라고 생각하시는게 제일 편합니다.
다시 말하면 구조체 포인터는 struct A와 같은 구조체를 가리킬 수 있는 포인터입니다.
struct A를 가리킬 수 있는 포인터는 다음과 같이 선언합니다.
struct A *pA;
예제를 바로 확인하겠습니다.
typedef struct {
int a;
int b;
} Array_a;
typedef struct {
int c;
int d;
} Array_b;
이렇게 두 개의 구조체를 선언했습니다.
main 함수 내의 코드는 다음과 같습니다.
int main(void) {
Array_a a1;
a1.a = 10; // 구조체의 이름은 배열의 이름과 마찬가지로 상수 포인터 역할을 함 (배열에서 [] 처럼)
// a1의 주소가 100일 때. a1.a는 100, a1.b는 104
a1.b = 20;
구조체를 선언하는 부분은 이전 게시물에서 다뤘으니 생략하겠습니다.
구조체의 이름인 a1은 배열에서 배열 이름과 동일한 상수 포인터 역할을 합니다.
따라서 . 연산자를 사용해 구조체 멤버를 가리킬 수 있고 위와 같이 구조체 멤버 변수에 데이터를 입력할 수 있습니다.
Array_a a2;
a2.a = 11;
a2.b = 21;
또 하나의 구조체 a2를 선언했습니다.
a1과 a2는 배열의 이름과 같이 구조체 멤버를 가리킬 수 있는 주소를 가지고 있습니다.
Array_a *pa1;
pa1 = &a1; // 지금은 구조체 a1을 가리킨다.
위와 같이 구조체 포인터 pa1을 선언하고, 같은 구조체인 a1의 주소를 참조했습니다.
포인터와 사용법의 완전히 동일합니다.
printf("(*pa1).a = %d\n", (*pa1).a); // = 10
printf("pa1->a = %d\n", pa1->a); // = 10
// 화살표 연산자는 (*). 연산을 편하게 하기위해 사용된다.
구조체 포인터가 참조하는 구조체의 멤버변수를 가리키기 위해선 위와 같은 두가지 방법이 있습니다.
(*pa1).a == pa1->a
두 방법은 동일한 역할을 합니다.
유래는 간단히 말하면 왼쪽 연산자가 복잡해서 오른쪽 연산자를 나중에 개발했다 정도입니다.
왼쪽 연산자의 원리는 단순합니다.
pa1에는 a1의 주소가 저장되어 있고, 해당 주소를 * 연산자를 통해 가리킵니다.
즉, *pa1 == a1이 되고, (*pa1).a == a1.a 와 동일합니다.
괄호를 씌우는 이유는 * 연산자의 우선 순위가 낮기 때문에 괄호가 없을 때 *는 a 앞에 붙은 것과 동일한 기능을 합니다.
pa1 = &a2; // 지금은 구조체 a2를 가리킨다.
printf("(*pa1).a = %d\n", (*pa1).a); // = 11
printf("pa1->a = %d\n", pa1->a); // = 11
위와 같이 pa1에 저장되는 주소를 a2의 주소로 변경하면, 동일한 연산을 했을 때 출력되는 결과가 a2의 멤버 변수에 저장된 데이터를 가져옵니다.
return 0;
}
1-2) 자기 참조 구조체
자기 참조 구조체는 구조체 멤버 변수로 해당 구조체를 참조하는 멤버 변수를 갖는 구조체입니다.
말이 좀 이상하죠?
바로 코드를 확인해보겠습니다.
typedef struct SRS{
int data1;
int data2;
struct SRS *p;
} srs;
위에 노란 박스 부분이 바로 자기 자신을 참조한 부분입니다.
단순히 생각하면 멤버 변수로 구조체 포인터를 하나 가지고 있는 것 입니다.
int main(void){
srs A = {11, 12, NULL};
srs B = {21, 22, NULL};
srs C = {31, 32, NULL};
위와 같이 구조체를 생성하고, 멤버 변수를 초기화 해주겠습니다.
NULL은 각각의 구조체 내부의 구조체 포인터가 가리키는 주소입니다.
A.p = &B;
B.p = &C;
각 구조체는 내부에 구조체 포인터를 가지고 있기 때문에 각자의 구조체 포인터와 위와 같이 다른 구조체 (혹은 본인도)의 주소를 저장할 수 있습니다.
printf("A.p->data1 = %d\n", A.p->data1); // = 21
printf("B.p->data1 = %d\n", B.p->data1); // = 31
구조체 A의 구조체 포인터 변수 p는 B를 가리키기 때문에 첫번째 printf 함수의 결과는 구조체 B의 data1을 출력합니다.
두번째 printf 함수도 마찬가지 입니다.
printf("(*A.p).data1 = %d\n", (*A.p).data1); // = 21
printf("(*B.p).data1 = %d\n", (*B.p).data1); // = 31
앞서 확인했던 -> 연산자와 (*). 연산자의 관계를 알아보기 위해 만든 구문입니다.
출력 결과는 동일합니다.
return 0;
}
자기 참조 구조체 (Self Referential Structure)도 끝!
1-3) 연결리스트 기초
아주 단순하게 연결리스트가 어떻게 구성되는지 알아보겠습니다.
개념은 위에 설명했기 때문에 생략하겠습니다.
typedef struct NODE{
int data;
struct NODE *next; // 자기참조 구조체 포인터 변수
// Struct NODE 타입의 주소값을 저장한다.
} node;
이렇게 NODE 기본 구조체를 선언합니다.
int main(void) {
node *head = (node *)malloc(sizeof(node));
head를 위와 같이 선언하는 부분은 지금 코드에만 사용될 수 있지만,
위와 같은 형식 (동적할당)은 아주 빈번하게 사용되니까 짚고 넘어가겠습니다.
원리에 대해 주변 선후배 동기들한테 많이 물어봤는데 명확한 확답을 듣진 못했습니다.
일단 head는 node 구조체를 참조할 수 있는 구조체 포인터 입니다.
하지만 node 멤버변수의 데이터 저장을 위한 메모리를 가지고 있지 않으므로
malloc 함수를 사용하여 메모리를 할당해줍니다.
이때 크기는 node의 크기입니다. (여기는 너무 당연합니다. node 내의 멤버변수를 저장해야 하니까..)
그리고 malloc이 void * 형 으로 반환되므로 node *로 좌우항의 자료형을 맞춰줍니다.
제 의문은 왜 sizeof(node)는 상수고, malloc은 그 상수만큼의 메모리를 할당해줬을 뿐인데
head는 node의 멤버변수인 int data와 struct NODE *next를 참조할 수 있을까?
왜 메모리가 각각 크기에 맞게 할당될까? (위에서 &a1과 같은 진짜 구조체로 할당된 것의 주소를 참조한 것도 아닌데...)
지인의 답변은 그냥 (node *) 해줄 때 메모리에서 멤버 변수의 위치가 정해진다고 생각하라는데 찝찝합니다...
아시는 분은 꼭 댓글로 부탁드려요...
각설하고 해당 구문을 사용하여 head에 메모리를 할당해주었을 때 아래와 같이 사용할 수 있습니다.
head->next = NULL; // 처음엔 가리키는게 없어서 NULL을 가리키고 있다.
처음엔 가리키는 대상이 없다가
node *node1 = (node *)malloc(sizeof(node));
node1->data = 10;
node1->next = head->next; // head가 가리켰던 NULL을 node1이 가리킨다.
head-> next = node1; // head는 node1을 가리킨다.
node *node2 = (node *)malloc(sizeof(node));
node2->data = 20;
node2->next = head->next; // head가 가리켰던 node1을 node2가 가리킨다.
head-> next = node2; // head는 node2을 가리킨다.
새롭게 node2를 선언해주고, 이때 node2의 주소를 0x02이라고 하겠습니다.
node2->next는 head->next가 가리켰던 0x01를 가리키게 되고,
head->next는 다시 node2의 주소인 0x02을 가리키게 됩니다,
정리하면 다음과 같습니다.

위와 같이 계속 head가 가리켰던 부분을 새로 생성되는 노드가 넘겨 받으며 연결 리스트를 늘려가게됩니다.
아래는 출력을 위한 부분입니다.
node *curr = head->next;
while(curr != NULL){
printf("%d\n", curr->data);
curr = curr->next;
}
구조체 포인터 curr은 head->next를 가리킵니다. (즉, node2를 가리킵니다.)
해당 구조체의 data를 출력하고 나면, 그 구조체의 next가 가리키는 구조체로 curr을 갱신합니다. (curr이 node1이 됩니다.)
free(head);
free(node1);
free(node2);
free(cur);
마지막으로 동적할당 받았던 메모리를 반환해줍니다.
return 0;
}
2) 연결리스트 ADT
이전 내용이 생각보다 많아 게시물을 분리했습니다.
다음 게시물에서 확인해주세요!
다음 게시물 링크
'Programming > C' 카테고리의 다른 글
| [자료구조 C 언어] C 프로그래밍 자료구조 - 7 : 연결리스트를 사용한 스택 (Stack) (0) | 2020.03.05 |
|---|---|
| [자료구조 C 언어] C 프로그래밍 자료구조 - 6 - 1 : 연결리스트 (Linked List) (추가, 삽입, 삭제, 검색, 뒤집기 등) (0) | 2020.03.05 |
| [자료구조 C 언어] C 프로그래밍 자료구조 - 5 : 배열을 사용한 큐 (Queue) (0) | 2020.03.04 |
| [자료구조 C 언어] C 프로그래밍 자료구조 - 4 : 배열을 사용한 스택 (Stack) (0) | 2020.03.04 |
| [자료구조 C 언어] C 프로그래밍 자료구조 - 3 (추가) : 희소 행렬 (1) | 2020.02.27 |